


TL;DR
- Solana's history is the complete, immutable record of every block since 2020
- Solana nodes keep a small part of it locally, pruning the rest to separate long-term storage (commonly BigTable)
- At the 400 TB scale, the standard architecture results in constant time-outs, high egress costs, and extremely limited access patterns
- We've solved it with Superbank, an open-source ground-up rebuild of the entire ledger
- It serves every standard historical JSON-RPC method (+gTFA) faster and cheaper by:
- Storing and compressing each column separately, cutting the bandwidth wasted decompressing whole blocks
- Skipping irrelevant data and avoiding re-sorting and processing at query time
- Isolating hot addresses, so heavy accounts can't slow everyone else down
- Keeping recent slots on fast disk and moving old history to cheap storage
- Enabling in-memory head cache for sub-1ms reads on recent slots
- Against public BigTable, Superbank is 5x faster on
getSignaturesForAddress, 38x ongetSignatureStatuses, and 3x ongetTransactionat P50
Introduction
Our new high-performance ledger pipeline, Superbank, went open-source last week as part of Triton's RPC 2.0 initiative. We've already covered the main drivers of the overhaul and its benefits for the ecosystem, so start here if you haven't seen it yet.
In this post, we'll go deeper into its architectural design: how the ledger works today, what a good historical pipeline should do, and the choices we made to deliver it.
Current historical pipeline
If you already know how Solana stores and serves history today, and where it falls short, you can skip ahead to the next section.
How history is produced
Solana's full history is one of the largest datasets in any blockchain ecosystem. At ~400ms slots and 1k+ TPS, it has produced over 400 TB of block and transaction data over the years:
- The leader for each slot batches the transactions it processes into a block and broadcasts it to the network as shreds, the small fragments that other nodes reassemble.
- Every validator and RPC node writes the blocks it receives into a local key-value store (RocksDB), which it uses to replay and verify blocks, take part in consensus, and answer recent queries quickly.
- To keep a node performant, its local store has to stay small, so older history is pruned locally and offloaded to permanent long-term storage.
How it's stored
For years, such storage was Google Cloud BigTable, which the Solana Foundation operates and populates at the end of each epoch. It was adopted early on as the practical choice, and hasn't evolved much since.
Pioneer RPC providers like Triton later replaced it with custom pipelines, such as Old Faithful and now Superbank, but the rest of this section covers the default implementation that some of the ecosystem still relies on.
BigTable stores history as a small set of 4 key-value tables, where you look up a row by exactly one key (index):
blocks, keyed by slot, whose value is the entire block compressed. This is the only place where full transaction bodies livetx, keyed by signature, whose value is a pointer: the slot and position where the transaction sits, plus its error and memo. The transaction itself isn't heretx-by-addr, keyed by address and slot, whose value is the list of signatures that touched that address in that slotentries, keyed by slot, used for Proof of History verification and rarely queried by builders

That layout is good at:
- High-throughput, append-only writes
- Immutable, cheap-to-keep storage
- Fast point lookups along its three keys (signature, slot, address)
Things start falling apart on everything past those fixed access paths:
- There's no server-side filtering: every read pulls a whole compressed block regardless of how many transactions a caller needs, burning compute and bandwidth
- Because of it, the egress (billed by bytes that leave the cloud) gets more expensive as the chain IBRLs
- The schema is frozen: adding a new kind of query means building a new table, decompressing the entire history, and re-scanning it to fill it
- Pagination only accepts signature cursors (
before/until), never a slot, time range, or offset, needed for modern apps
How it's queried
Builders read this history through an RPC node. They send a JSON-RPC request, and if the node doesn't have an answer in its local store, it calls BigTable.
BigTable then looks up the key across its tables, decompresses the blob, and hands it back for the node to decode into the JSON-RPC response.
That's several round-trips and a lot of processing for even a simple question, which is why most historical queries are neither fast nor cheap.
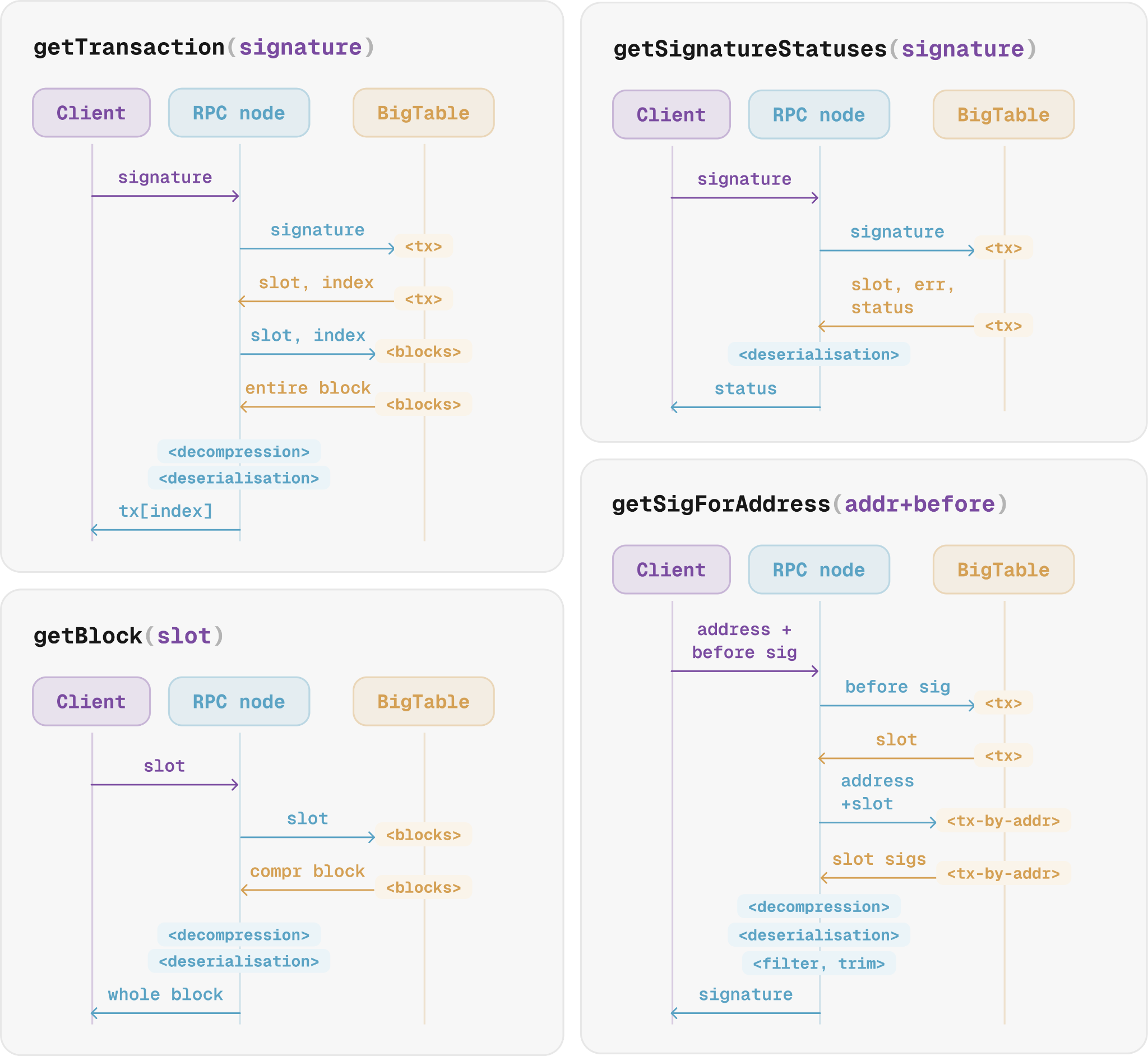
The current JSON-RPC works well for extremely narrow cases, like fetching an account's raw signature list or confirming a transaction's status.
As soon as you reach past that: deep history, pulling a few transaction fields quickly, or an entire wallet's history, you get unavoidable overhead, plus often client-side looping, parsing, sorting, and deduping on top of it.
"Perfect" architecture checklist
The limitations above have nothing to do with Solana's volume or speed. They're the downstream result of a pipeline built as an MVP and never optimised for the actual access patterns.
To fix that, you have to treat it as a big-data problem and rethink each sub-component from the ground up, around the results it has to deliver for every side that interacts with it:
For the validators writing to it, it has to:
- Accept writes in real time
- Handle high-throughput write pressure
- Stay append-only and immutable
For the team or provider hosting it, it has to:
- Stay lightweight while holding hundreds of terabytes
- Keep queries cost-efficient across that volume
- Stay flexible enough to add new methods and filters as the ecosystem's demands evolve
- Scale easily as throughput, consumers, and total history grow
For the builder querying it, it has to:
- Return responses fast
- Allow optimisation through filters and pagination
- Support expressive queries (like
getTransactionsForAddress) - Stay affordable and don't waste bandwidth or requests
- Be highly available and responsive under load
Put together, that's an immutable, multi-terabyte dataset written at extreme throughput that nonetheless has to stay cheap and quick to query in expressive ways.
That's the challenge Superbank was built for.
Superbank's modular infrastructure
A historical pipeline must scale across writes, storage, and reads, so it shouldn't reside within a single monolithic process where every workload competes for the same hardware, cache, and I/O.
Instead, each of those 3 jobs should run as an individual component:

This also allows Superbank to keep up with any volume without sacrificing performance: each component scales independently, and the same data can be partitioned (split into chunks) and sharded (replicated across multiple servers) when a single node isn't enough.
Ingest
The ingestor's job is deliberately narrow: pull blocks and transactions from a source, decode them into rows, and flush them to ClickHouse. To achieve maximum throughput on writes, it doesn't filter or transform the data in any way, ingesting everything as-is.
It's source-agnostic, with built-in support for Dragon's Mouth gRPC, BigTable, JSON-RPC, and Jetstreamer, so you can backfill from an existing archive and switch to a live stream without rewriting the pipeline.
Storage
Reading Solana's history looks like an analytics workload. Builders call a small, fixed set of JSON-RPC methods that scan many rows, return only a few columns, often reach deep into history, and rely on the server to do the sorting and filtering.
That calls for a column-oriented queryable database, ClickHouse. It enables:
- Columnar storage. Each column is stored separately, so a query reads only the data it needs. If a call asks for just signature, slot, and status, ClickHouse skips the other 64 columns.
- Insert-time materialised views. Every write to the base table also produces a derived copy, transformed for a specific query, built in the same insert rather than at query time.
- Sorted primary keys. Each materialised view is sorted around the query it serves, so a matching query jumps straight to the rows it needs instead of scanning the whole table.
- Per-column compression. Same-type columns compress much more efficiently, so the footprint stays small without slowing reads:
Delta+ZSTD(1)for sequential numbers likeslot,ZSTD(3)for large repetitive blobs, andZSTD(1)everywhere else. - Tiered storage. ClickHouse enables you to easily move data across storage tiers as it ages: NVMe for recent epochs, HDD for older epochs, and S3 for deep history, so you tune cost against retention without touching the schema.
Schema
The incoming data stream is written into two base tables, blocks_metadata and transactions, both keyed (and queried) by slot.
On every write into transactions, ClickHouse derives materialised views from it, each sorted the way its query reaches the data: by signature for gSS, by address for gSFA, and by token owner for gTFA.
A few more optimisations sit on top:
- All the views are stored and read newest-first, so every query locates what it needs up front
transactionstable carries a bloom filter on signature: a lightweight check that lets a lookup skip the chunks that can't contain a given signature.- On disk, the
gsfatable is sorted by address, so all of an address's transactions sit together. An optionalgsfa_hotschema re-partitions thegsfaview for very high-traffic addresses, such as the USDC mint, spreading the reads across the whole cluster. - gSFA skips four system addresses that appear in nearly every block, but aren't usually queried: System, Vote, Sysvar Clock, and Sysvar Slot Hashes.
- gTFA filters address history by slot, block time, status, and token activity, while gSFA and gT take slot bounds (
beforeSlot/afterSlot, a slot hint) for speed.
Because the data is columnar and pre-sorted, the heavy lifting runs at the storage layer, saving you bandwidth and the client-side work of filtering, sorting, and deduping the results.

Query layer
The query layer is a standard Solana JSON-RPC server with one additional method: getTransactionsForAddress, returning an address's full history in a single call.
Under the hood, every lookup is converted into a performant SQL query, tuned to the tables' physical sort order, so latency stays low across the board.
For the most recent reads, a head cache subscribes to an upstream gRPC stream and holds the newest slots in memory, delivering the latest data in <1ms, with processed-commitment freshness.
Two more caches keep repeat reads at the lowest latency:
- A query cache stores recent results for a default time span;
getTransactiongets a 300-second TTL since finalised transactions never change, while other methods use a shorter default. - A slot synchroniser keeps the latest slot number in memory and refreshes it every 200ms, so
getSlotnever hits storage.
If the dataset is spread across several machines, a query routes in one of two modes:
- Distributed goes through ClickHouse's coordinator, which fans the query out to every shard and merges the results (best for queries spanning multiple servers).
- Shard-direct uses Superbank as the coordinator and queries only the required shards directly, skipping a network hop and decreasing latency.
To-date results
These architectural choices allow us to achieve order-of-magnitude-faster reads across the entire Solana ledger.
| getSignaturesForAddress | P50 | P90 | P99 |
|---|---|---|---|
| BigTable | 245ms | 332ms | 359ms |
| Superbank (ClickHouse) | 50ms | 131ms | 398ms |
| getSignatureStatuses | P50 | P90 | P99 |
|---|---|---|---|
| BigTable | 1,885ms | 2,321ms | 2,545ms |
| Superbank (ClickHouse) | 49ms | 240ms | 543ms |
| getTransaction | P50 | P90 | P99 |
|---|---|---|---|
| BigTable | 460ms | 633ms | 777ms |
| Superbank (ClickHouse) | 138ms | 384ms | 950ms |
However, it's only the beginning. As we go into 2026, we'll keep optimising the individual components and IBRL the entire stack.
Run it yourself, or leave it to us
At Triton, we believe Solana grows fastest when its underlying layers are open.
Historical data has always been on-chain, but the way the ecosystem could access it remained locked behind a few closed-source endpoints.
Superbank opens it up, giving every team and provider the most performant pipeline for ingesting, indexing, storing, and serving Solana's history end-to-end.
And if you'd rather not operate it, or you need global geo-distribution, redundancy, and uncompromising reliability, we offer it as a managed service.
The architectural efficiency that makes Superbank faster also makes it cheaper for us to run, so we've dropped historical reads to the same price as standard RPC, regardless of epoch or method: $10 + $0.08/GB per request.