


TL;DR
- AccountsDB, the validator's built-in account store, was made for the runtime: single-account lookups at enormous parallelism during transaction execution
- Set queries (gPA) were never its job, so they fall back to scanning, with filters applied only after each account is loaded into memory
- Custom indexes fix it, but they live in the validator's RAM, require an Agave patch and a node restart, keeping them exclusive to dedicated-node setups
- Cloudbreak removes that limit, serving indexed account reads over 99% faster and 7x cheaper from shared infrastructure by:
- Decoupling the account serving from the validator
- Keeping every account's latest version in a Postgres database
- Partitioning by program owner, with dedicated fast paths for token queries
- Creating indexes from live traffic after the first-seen request
- Sending large results back in chunks, with no response-size cliff or timeouts
- We solved the challenges of efficiently storing and serving 1.1B+ accounts in the open, giving any team a plug-and-play pipeline for building expressive apps on Solana
Introduction
Cloudbreak is the accounts pipeline of the RPC 2.0 initiative, a Postgres-backed read layer that makes fetching Solana state feel like querying a database.
The launch post covered what shipped and why the ecosystem needed it. In this blog, we'll go deeper into how we did it: what account reads look like on Solana today, what a replacement had to deliver, and the design choices behind every component we built.
Everything is an account
Solana has only two data primitives. The transaction records events. The account holds the current state of everything: your wallet, each token balance you hold, a DEX market, and the program code behind it.
Every account is owned by a program allowed to change its data or debit its lamports. Your wallet is owned by the System Program; your token balances are owned by the Token program; DEX markets and orders are owned by that DEX's program; deployed programs belong to a loader; and the chain bottoms out at the Native Loader, hardcoded into the validator itself.
Each of these on-chain accounts is just a small envelope of fixed fields plus a data blob containing raw bytes.
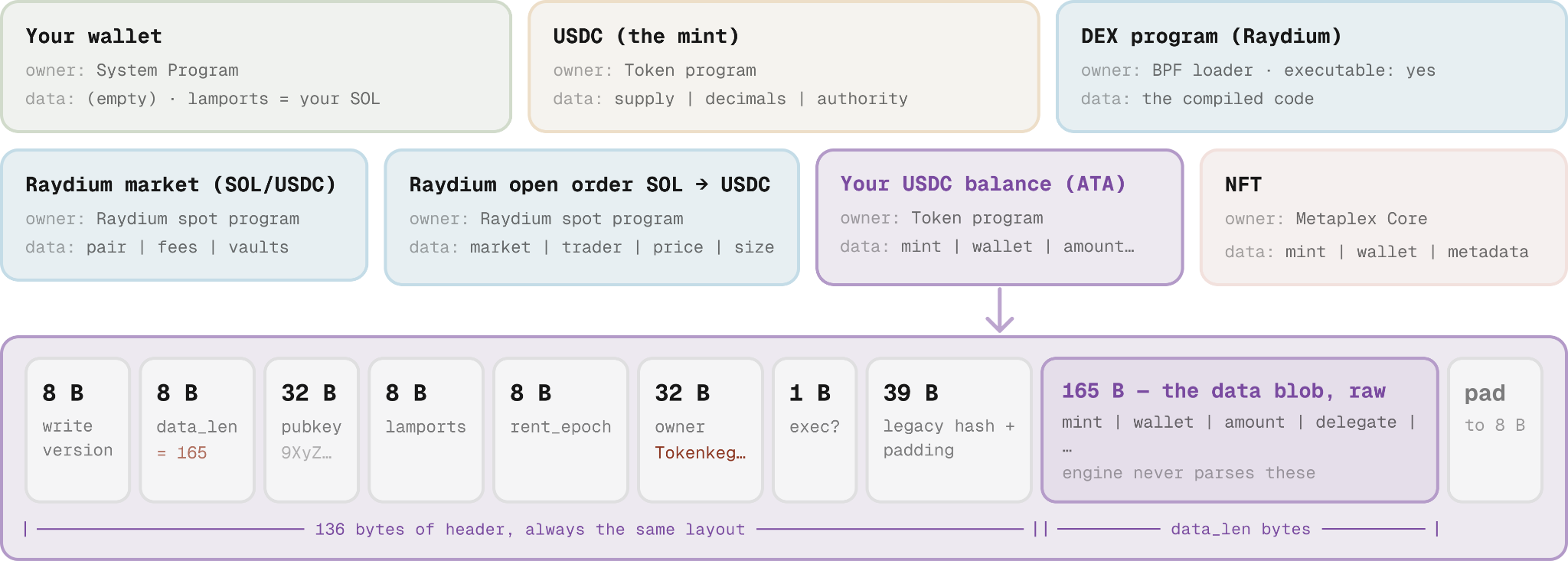
Five fields are known and predictable, identical in shape and position on every account: address (32 bytes), lamports (8), owner (32), the executable flag, and a rent epoch.
Everything else lives in the data field, where the owner program stores whatever its job requires (a mint, an owner wallet, open orders, and so on) in a layout it defines.
AccountsDB pipeline
Solana's state turns over constantly: every transaction calls programs to update the accounts they own, across a live set of 1.1B+ accounts.
Holding that state, reading and writing individual accounts, is the job of AccountsDB: the storage engine hardcoded into the validator client, purpose-built for transaction execution at massive parallelism.
Under the hood, it's a hash map over memory files with no query language or sorted order. The one question it answers natively is "give me account X", and it answers it extremely fast.
Here's how it works:
- The leader broadcasts the block in shreds to other nodes via Turbine.
- Every node then reassembles it and replays the transactions: the runtime invokes the programs with the provided instructions, reading the accounts from AccountsDB.
- Replay runs in the Bank (the node's working copy of state for that slot), and each transaction writes new versions of the accounts it modifies into a RAM buffer.
- When the slot is finalised, those buffered versions are appended to the slot's file on disk.
- The main index is updated to map each pubkey to the locations of its processed, confirmed, and finalised versions.
- Background cleanup deletes superseded versions (after finalisation) and zero-lamport accounts, keeping the set bounded.
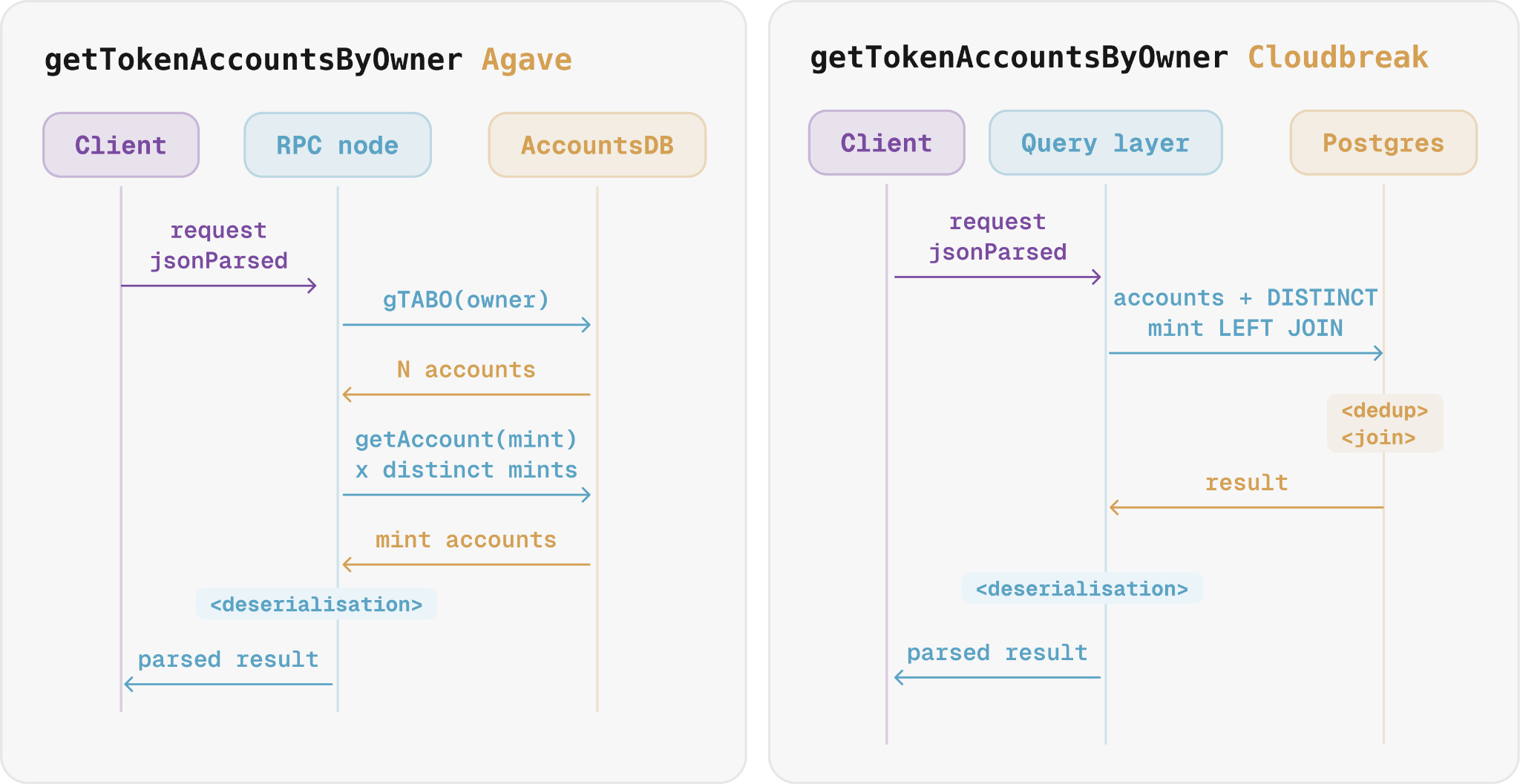
The JSON-RPC interface sits on top, alongside three native indexes: program to its accounts (scoped by operator, token program is generally excluded), mint to its token accounts, and wallet to its token accounts, built by slicing known bytes from each account at write time.

When a call names a pubkey or hits a token index, it's just an index lookup and a read, so it stays fast: getAccountInfo, getBalance, getMultipleAccounts, getTokenAccountBalance, getTokenAccountsByOwner.
getProgramAccounts is the set query with no native path: nothing groups a program's accounts on disk. The node has to scan every account on the chain, testing owner == P, or, with the optional program index on, to walk the program's membership list and load each account, one scattered disk location at a time. Either way:
memcmpanddataSizefilters run in Rust after each account is loaded.- gPA on a program that owns 5M accounts always costs 5M loads per request (more if the program-id index is disabled), even when only 200 match the filter.
- The whole result is assembled in memory and returned as a single payload, with no easy way to paginate, sort, or cap it.
Building an index
Solana's native account indexes (program-id, token-owner, token-mint) are off by default, enabled per node with a startup flag, held entirely in RAM (~256 GB per index), and rebuilt on every boot.
To index anything else, like the bytes a memcmp targets or an account's dataSize, you'd have to fix the shape ahead of time, patch the validator client to support it, and run that on a dedicated node.
This kept fast, indexed reads out of reach for most of the ecosystem, and too rigid even for the workloads that could afford them.
Requirements of a better pipeline
Fixing the read path for Solana accounts came down to four things:
It had to be accessible. Serving accounts from Agave means validator-class hardware and engineering overhead, so the work needed to move to a separate pipeline that runs on commodity machines and is simple enough for any developer to operate.
It had to stay correct. Living outside the validator, the copy needed to track the chain through forks, gaps, and restarts, and return exactly what Agave would across every commitment level and encoding.
It had to be performant across all the methods. The new pipeline needed to match AccountsDB on point lookups while delivering expressive set queries at the same low latency. That meant building indexes from live traffic on the fly.
It had to be scalable and future-proofed. The same pipeline had to work for a solo developer, a growing startup, an institution, and a commercial provider. Starting with a light index of a few programs and growing it into one that covers the full chain had to be seamless and require no rewrite of the base layer.
Cloudbreak's modular infrastructure
A single process owning every job means they all degrade together, which is why Cloudbreak breaks the work into separate components.
Each runs as its own service around a Postgres database that holds the latest version of every account: an indexer writes the incoming stream to rows, a stateless API answers queries, and a query tracker watches traffic and creates new indexes on the fly.
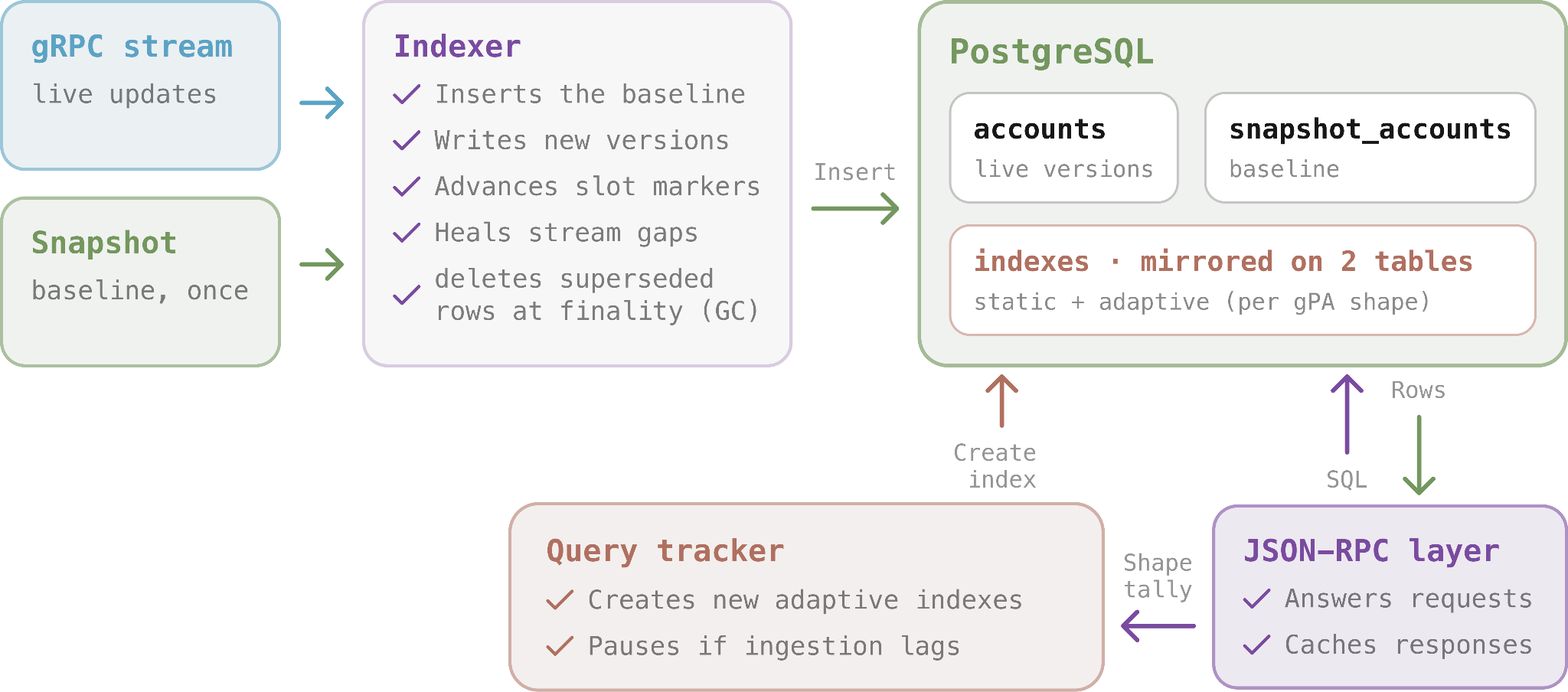
Modularity also removes the one-to-one tie between different processes: one Dragon's Mouth stream can feed many database instances, one Postgres can serve many stateless API layers, all scaling independently.
Indexer
At startup, the indexer loads a recent accounts snapshot (a point-in-time copy of the entire account set) that nodes use to bootstrap without replaying history. It sorts the accounts by owner and writes them into the snapshot_accounts baseline table.
Then it subscribes to the gRPC stream at confirmed commitment and writes each updated account into Postgres as a new row, stamped with its slot.
Once all of a slot's accounts are written, it advances the readable-slot marker (slot number the query layer reads up to). This way, a confirmed read always sees complete data and never lands on a half-written slot.
It also watches for gaps: if the stream skips slots, the service reports them via getHealth and backfills the missing slots from an incremental snapshot before recovering.
Postgres storage
Solana's live account state is bounded: only the latest version of each account matters at query time, updates are append-only, and reads fetch whole records by key.
That makes a row-oriented Postgres database the natural fit, covering much of the required functionality out of the box:
- Operational maturity. Open-source, established pooling, timeouts, and monitoring, and a broad community that knows how to operate it.
- Indexes on live data.
CREATE INDEXover any expression runs in one statement with no downtime, which is what lets the query tracker add indexes on the fly. - Native index maintenance. Postgres keeps every index, static and adaptive, current on each insert; the indexer and query tracker never update one themselves.
- Instant "latest version" resolution.
DISTINCT ON (pubkey) BY slot DESCreturns the newest version of each account across the live and baseline tables. - Garbage collection is plain SQL. Superseded versions and zero-lamport accounts are removed via DELETEs, and autovacuum frees the space for reuse by later inserts.
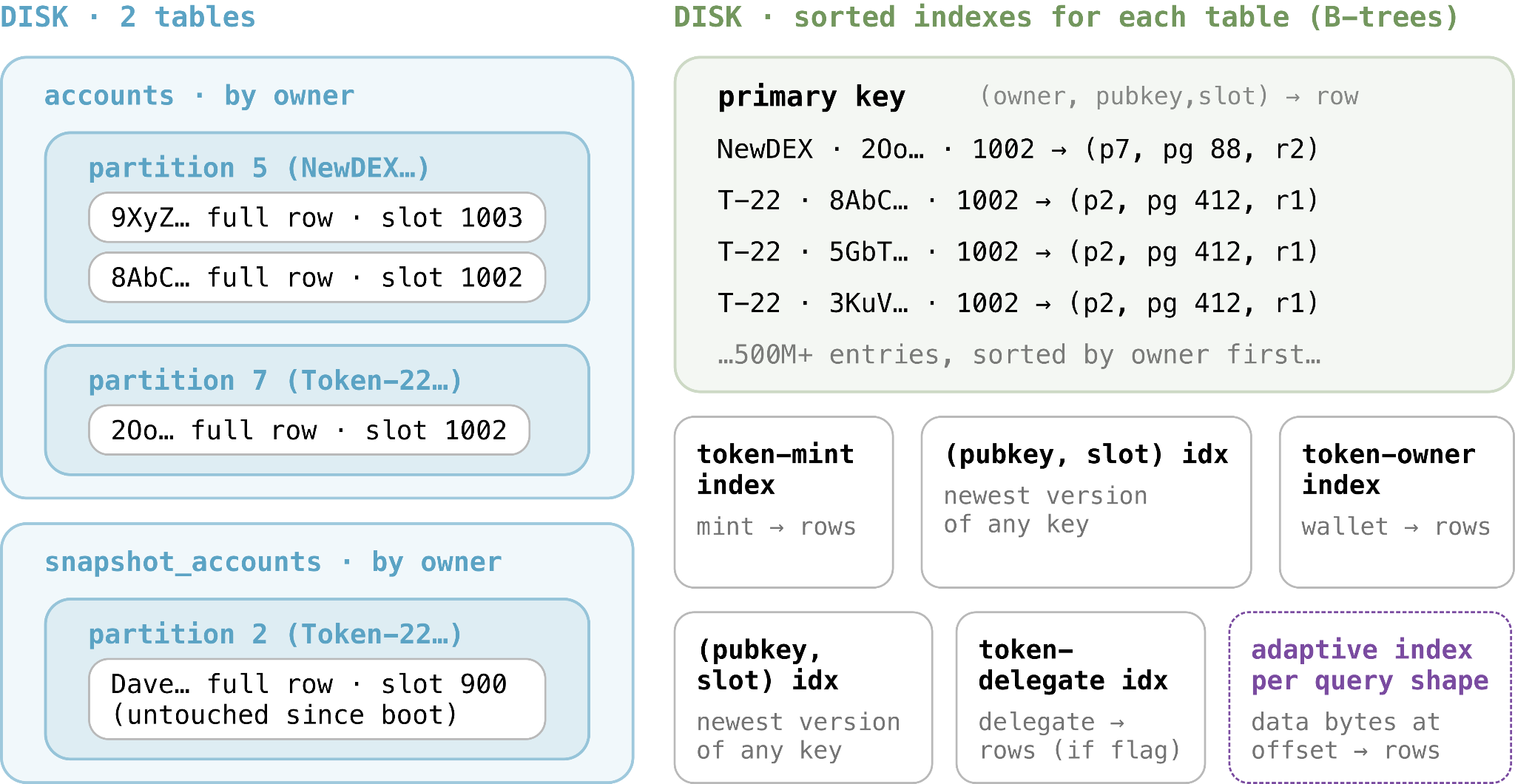
In addition to what Postgres delivers natively, Triton's schema introduces three additional optimisations:
New state is separated. The baseline lives in snapshot_accounts, shrinking over time to just the accounts untouched since boot, while the live stream writes only to accounts. Reads union the two and keep the newest version of each account.
Owner is the partition key. Both tables are partitioned by owner (hashed for even distribution) into sub-tables on a single server. Since every gPA filters owner = P, Postgres drops all other partitions up front, and the (owner, pubkey, slot) primary key keeps the program's rows contiguous within its partition. This way, even an unindexed gPA becomes a fast sequential read.
Token queries get a fast path. Postgres extracts the mint and owner wallet into stored columns on write, and indexes mint, owner, and delegate for token-program rows, turning a standard token filter into a direct lookup.
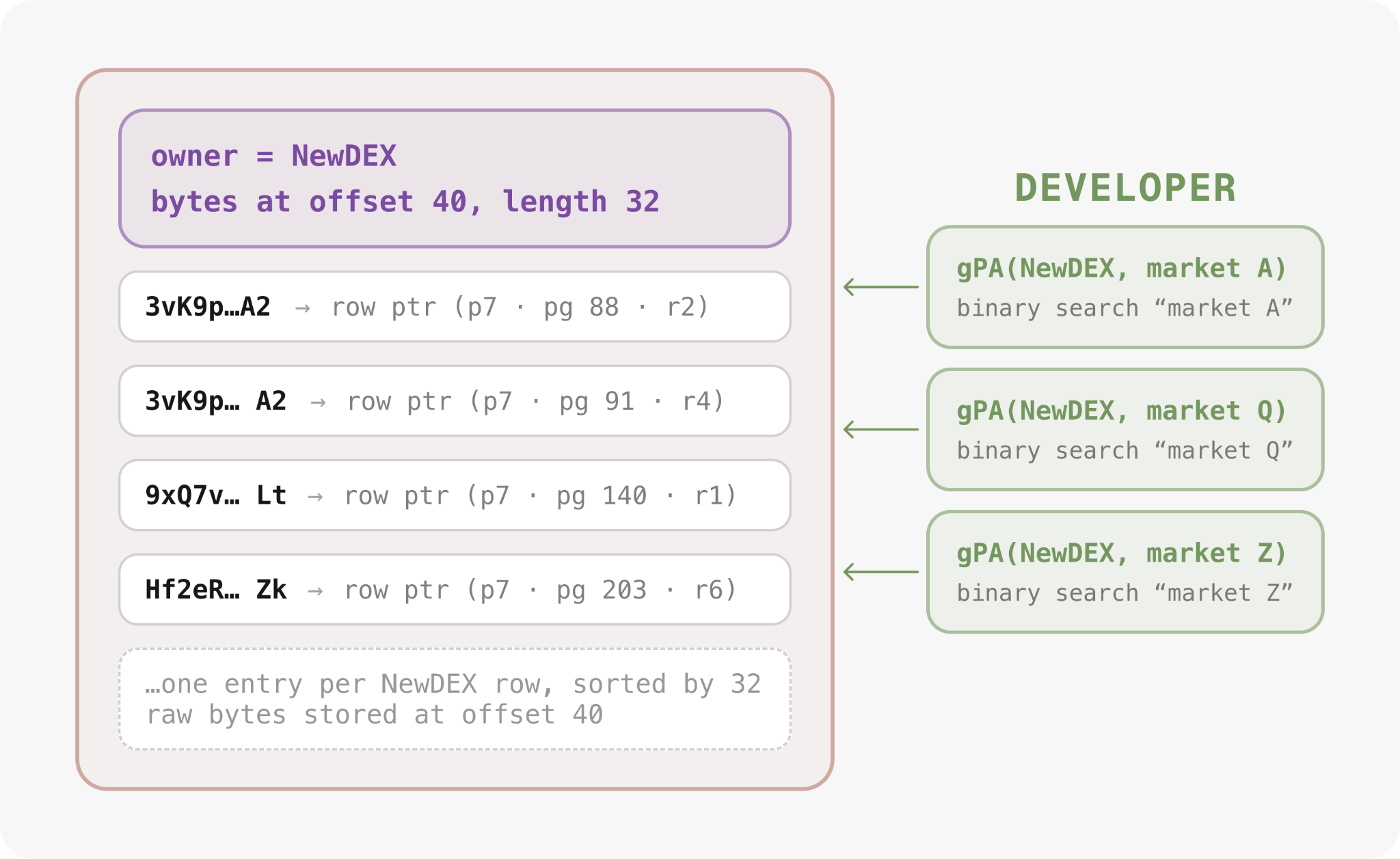
gPA query tracker
The query tracker handles dynamic indexing: it records every getProgramAccounts filter shape and builds a matching index once one crosses the configured threshold.
Index creation runs one at a time, 10 seconds apart, pausing when ingestion lags to avoid competing with writes. Scoped to one program and one shape, each index serves every value at that shape from a single sorted structure.
Query layer
The API is a stateless JSON-RPC server that serves the standard account and token methods (plus a new getTokenAccountsByMint method) at the confirmed and finalised commitment levels.
Under the hood, every request becomes a single SQL statement that retrieves the latest version of each account, unions the live and baseline tables, filters out zero-lamport accounts, and applies your byte filters against any existing indexes.
The effect is clearest in jsonParsed responses, where formatting a token balance requires the mint's decimals. Triton's query layer collects and joins all the mints in a single batched pass, collapsing thousands of separate lookups into one.
We introduced two more optimisations at this layer:
- Streamed responses. Data leaves the server in small chunks as rows are read, so a large gPA starts arriving immediately and never hits a response-size cliff or a buffer-building timeout.
- Cached repeat polls. On a repeat of the same query, Postgres returns full data only for rows changed since the last answer and bare pubkeys for the rest; the API refills the unchanged rows from its cache and returns the complete result.
Benchmarks
For gPA, Triton's new architecture drops latency from seconds to milliseconds, scaling with the size of the answer rather than the program or the entire account set. Here is the full run, broken out by response size and encoding (N is the number of requests in each bucket):
getProgramAccounts, base64:
| Response size | Endpoint | Avg (ms) | P50 (ms) | P90 (ms) | P99 (ms) |
|---|---|---|---|---|---|
| 1-10KB (N=662) | Agave | 1,725 | 2,297 | 2,478 | 6,348 |
| Cloudbreak | 4 | 4 | 5 | 11 | |
| 10-100KB (N=244) | Agave | 2,725 | 4,194 | 4,699 | 6,386 |
| Cloudbreak | 7 | 5 | 11 | 42 | |
| 100KB-1MB (N=181) | Agave | 3,971 | 4,476 | 4,693 | 5,464 |
| Cloudbreak | 8 | 7 | 13 | 23 | |
| 1MB-10MB (N=53) | Agave | 3,693 | 4,487 | 4,708 | 5,608 |
| Cloudbreak | 47 | 12 | 25 | 694 | |
| 200MB-500MB (N=22) | Agave | 2,005 | 1,866 | 2,851 | 3,086 |
| Cloudbreak | 564 | 526 | 678 | 730 |
getProgramAccounts, jsonParsed:
| Response size | Endpoint | Avg (ms) | P50 (ms) | P90 (ms) | P99 (ms) |
|---|---|---|---|---|---|
| 0-1KB (N=9) | Agave | 5,592 | 5,572 | 5,793 | 5,954 |
| Cloudbreak | 4 | 4 | 5 | 5 | |
| 1-10KB (N=1) | Agave | 5,667 | 5,667 | 5,667 | 5,667 |
| Cloudbreak | 4 | 4 | 4 | 4 | |
| 10MB-50MB (N=8) | Agave | 708 | 626 | 1,016 | 1,029 |
| Cloudbreak | 280 | 266 | 284 | 377 |
Measured end-to-end within a single datacenter to isolate query latency from network transport.
Final words
Almost every Solana application depends on account state, from wallets and explorers to DEXs and trading desks. Until now, reading it at scale meant going through rate-limited gPA endpoints, running a dedicated node for $3,000+ a month with fixed index shapes, or accepting vendor lock-in behind a closed API you can't customise.
Cloudbreak eliminates these trade-offs, letting you run a full-chain instance with custom indexes on a commodity Postgres box for under $400 a month.
It brings Solana tooling a step closer to the simplicity and completeness of a web2 full-stack, and we're proud to be laying that groundwork. The exact pipeline that serves our production traffic is now open source under AGPL, in the solana-rpc organisation, free for any team to run, extend, and fork.
If you need enterprise-grade reliability out of the box or want to skip the operational overhead, Cloudbreak is enabled by default on every Triton endpoint.