

TL;DR
- Solana's monolithic RPC architecture has been penalising the ecosystem for years, resulting in high costs, design limitations, fragmented tooling, and additional Turbine load
- Moving reads onto purpose-built pipelines was the obvious step; making it performant, spec-compliant, Agave-compatible, and open-source all at once was the hard part
- For months, we've been rebuilding and optimising two systems: Cloudbreak indexes for fast account requests and Superbank ledger for smart history access
- Any team can now run on the most performant read layer from day zero, dropping the cost of entry, the friction of migration, and the cycle of closed-source workarounds
- It’s our first contribution to
solana-rpc, the new organisation where the Solana RPC working group (Foundation and community members) IBRLs the read layer in the open
The state of reads on Solana
Agave's monolith puts consensus and lowest-common-denominator read queries in the same process, with older history offloaded to BigTable.
At launch volumes, that architecture held up without much strain, but as the chain scaled past hundreds of millions of transactions a day, it began to produce more problems than it solved across reads’ performance, cost, and accessibility.
Slower responses and lower limits
A single Agave node now handles consensus, account updates, fork resolution, blockstore writes, and every JSON-RPC query at once, sharing memory, I/O, and CPU across the whole workload.
When a DEX calls getProgramAccounts, it competes with a gRPC subscriber streaming state changes, and both share the node's resources with shred ingest from Turbine and slot writes into AccountsDB.
History compounds the problem: the local blockstore only covers recent slots, so older lookups become a network round trip to BigTable, and canonical N+1 patterns for fetching address history further multiply that overhead across hundreds of dependent calls.
Our benchmarks against a reference Agave node and BigTable show what that costs the ecosystem in performance:
| Method | Backend | P50 | P99 |
|---|---|---|---|
| getProgramAccounts (100KB–1MB, base64) | Agave | 324 ms | 6.9 s |
| getProgramAccounts (100KB–1MB, jsonParsed) | Agave | 6.2 s | 6.6 s |
| getSignaturesForAddress | BigTable | 245 ms | 359 ms |
| getSignatureStatuses | BigTable | 188 ms | 2.5 s |
| getTransaction | BigTable | 460 ms | 777 ms |
The benchmarks ran at light traffic (7.3 RPS) – production load pushes latencies higher. To keep the node from falling behind the tip, operators throttle request rate, cap concurrent connections, and tier-gate the heaviest methods.
Not to mention, the JSON-RPC code lives inside the validator binary, limiting how far consensus and execution can be pushed without breaking RPC behaviour.
Linearly-increasing costs
The traditional read path scales costs linearly with traffic. As load grows, operators spin up more nodes to keep responses fast, and each one has to meet validator-class specs: 768 GB of RAM, fast NVMe for AccountsDB and the recent blockstore, and high-bandwidth networking for ingest. The software was built around those numbers, so even an unstaked read node inherits the same hardware “minimums”.
This way, every query above the current capacity results in another multi-thousand-dollar deployment. The ecosystem pays for that a second time over the network – as new RPC nodes join Turbine, it forces the chain to push more shreds, slowing data propagation for everyone.
Ironically, read traffic needs almost none of it: a gPA call for one program is served (and much faster) from a light index, without walking the full account set in RAM.
Fragmentation of closed-source tooling
Performance and cost challenges pushed many teams to build their own pipelines around Agave’s monolith, each behind a closed API with quirks, gaps, and backends that weren't designed to interoperate.
The result is lock-in and limited access:
- Switching providers becomes impractical for any large codebase
- Performance gains never compound across the ecosystem
- The most performant read path concentrates behind a few providers' endpoints, while only the raw data remains "open"
RPC 2.0 ships open-source
Today's release finally solves all three problems and adds the missing pillar to the open Solana standard: RPC 2.0.
Two repos are live, with deployment-ready software and the docs to run them in production.
Cloudbreak: accounts module
Agave answers getProgramAccounts by scanning the entire account set on every call (the source of the 6.9s P99 response times). Cloudbreak replaces that with indexed lookups that build themselves from your traffic.
Beyond gPA, it serves token queries via denormalised columns by mint, owner, delegate, direct account lookups, and the standard utility methods.
Here's how it works:
- Bootstrap (first start only). The HTTP sidecar downloads a Solana snapshot concurrently and writes it to
snapshot_accountsas the baseline - Subscribe. The indexer connects to a Dragon's Mouth (Yellowstone gRPC) stream and starts receiving account updates
- Filter and store. Updates are filtered against your program scope (TOML include/exclude lists) and upserted into the accounts table
- Index adaptively. Query tracker monitors the API's filter patterns and creates a targeted Postgres index whenever one recurs past the threshold
- Serve queries. The stateless JSON-RPC API runs each request against snapshot_accounts and accounts, using whichever indexes have been built. Token program calls auto-route to denormalised fast-path columns
- The supported method set covers account queries (
getProgramAccounts,getAccountInfo,getMultipleAccounts,getBalance,getTokenAccountBalance), token queries (getTokenAccountsByOwner,getTokenAccountsByDelegate,getTokenAccountsByMint), and utility methods (getSlot,getHealth,getVersion,getGenesisHash) - Stay healthy. Finalised slots trigger garbage collection of superseded versions, and slot gaps in the stream trigger automatic recovery from incremental snapshots
The diagram below shows how these sub-modules fit together. We'll go deeper into design rationale and self-hosting in the next posts in the Rethinking series.
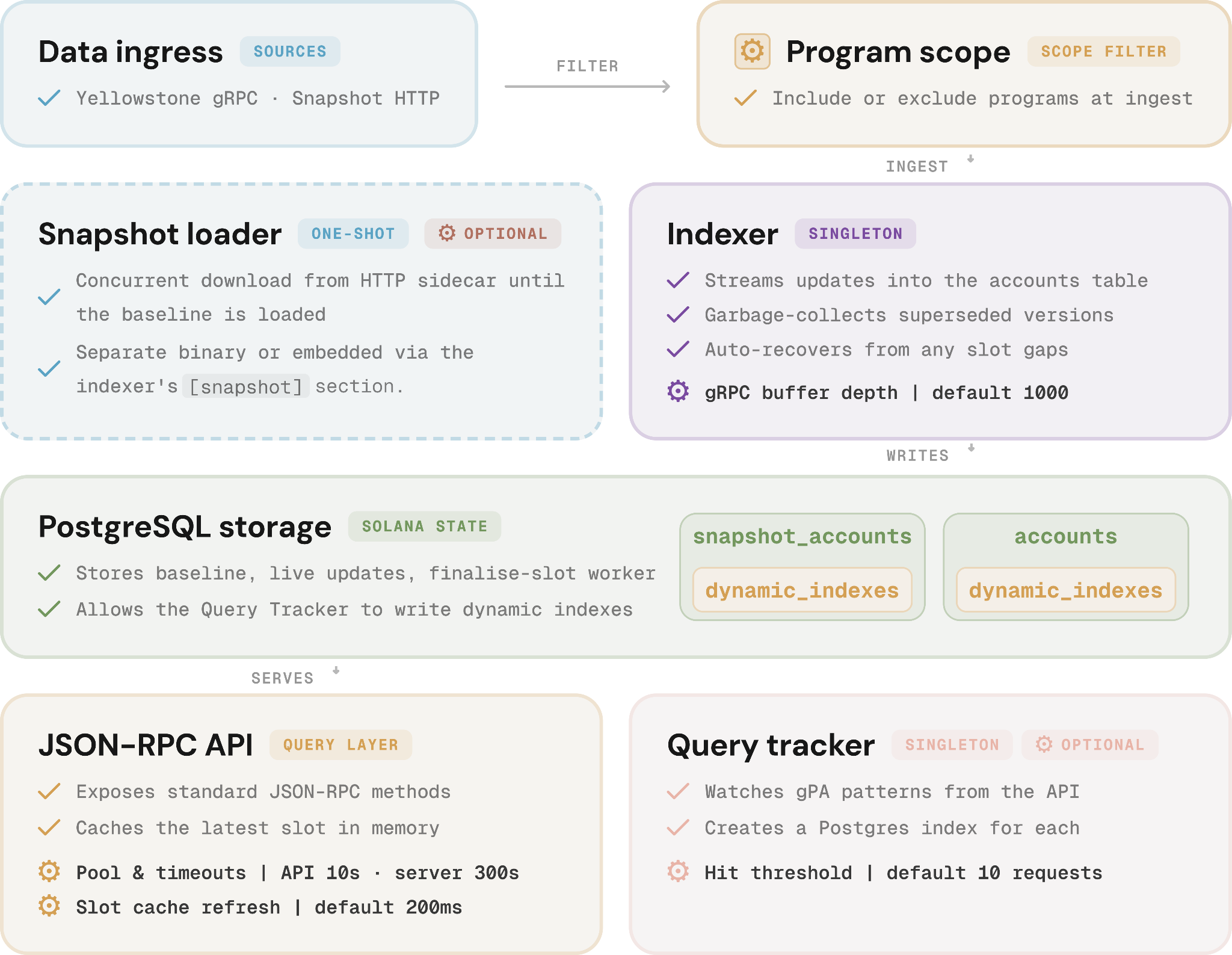
Cloudbreak bends to your query patterns, letting you build expressive Solana apps without a dedicated node.
And because the workload is bounded, it stays affordable: a full-chain instance with 200 indexed query patterns fits in ~700 GB of storage and runs on a medium bare-metal Postgres node for <$400/month.
Superbank: historical module
Superbank is a ground-up rebuild of Solana's historical ledger, designed around how developers query history. ClickHouse handles the scale natively: columnar storage lets queries fetch only the columns they need, materialised views derive per-method projections at insert time, and every table is physically sorted by the query patterns.
End-to-end flow:
- Pick a topology. Choose the deployment that matches your scale: local for single-node development, cluster for sharded production deployments, and replicated for sharded deployments with ZooKeeper-managed copies
- Ingest. The ingestor pulls block and transaction data from your source of choice (gRPC stream, BigTable backfill, upstream JSON-RPC, or JetStreamer plugin), decodes it into rows, buffers in memory, and flushes batches to ClickHouse without filtering
- Auto-derive views. As rows land in
transactionsandblocks_metadata, ClickHouse derives method-specific materialised views at insert time, moving query-time work upfront - Route the query. The RPC server reads from ClickHouse, choosing between distributed queries (for cross-shard coverage) and shard-direct fan-out (for lower-latency point lookups)
- The supported methods cover transaction lookups (
getTransaction), signature queries (getSignaturesForAddress,getSignatureStatuses), block-level queries (getBlock,getBlockHeight,getBlocks,getBlocksWithLimit,getBlockTime,getFirstAvailableBlock), and the standard utility methods (getSlot,getLatestBlockhash,getTransactionCount,getInflationReward) - Hit the head cache (optional). When enabled, recent slots resolve from in-memory state in < 1ms, making processed commitment available on historical methods for the first time
The diagram below shows how these work together:
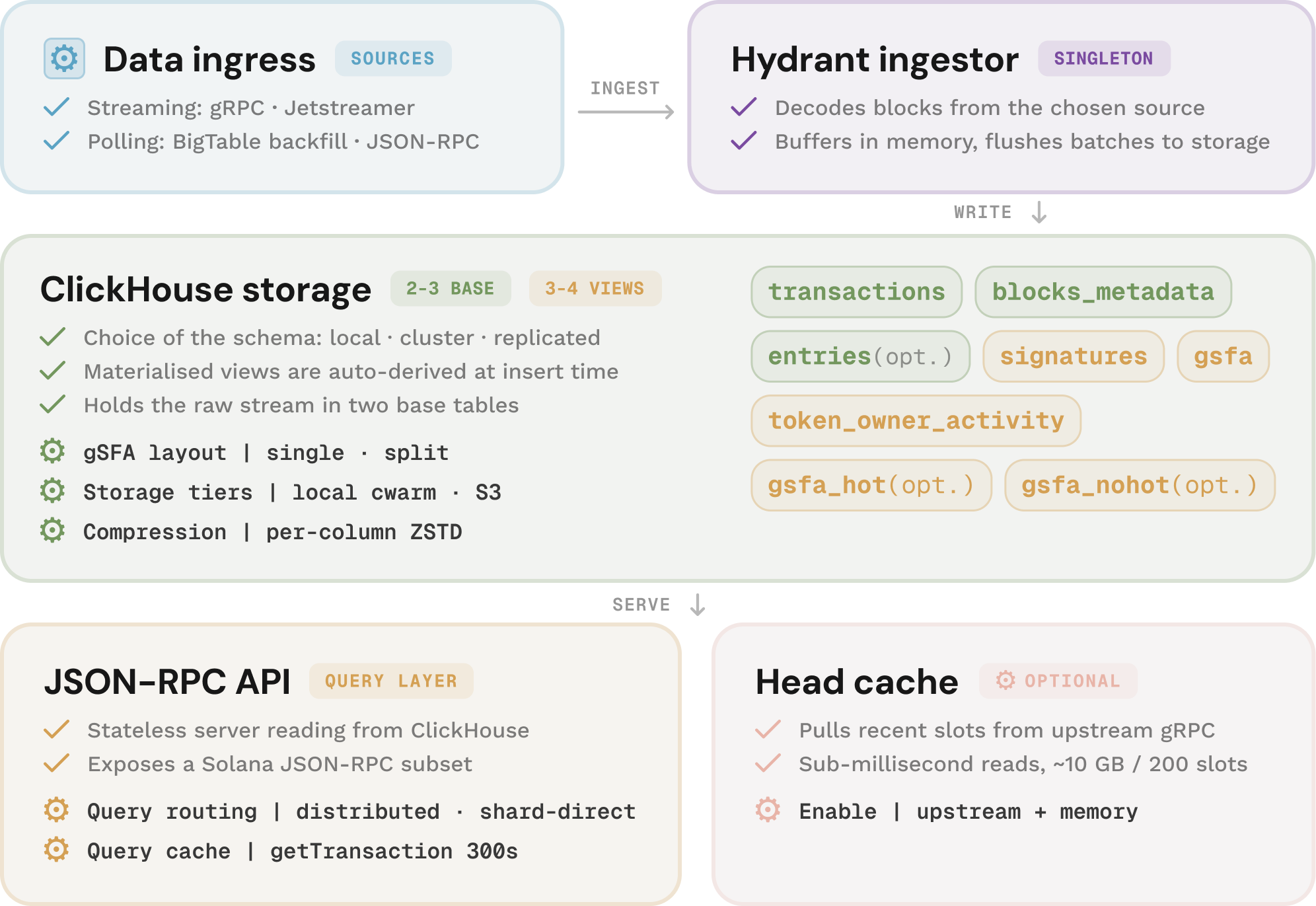
Whether the use case is compliance, analytics, research, or backtesting, Superbank is a plug-and-play Rust backend for any team that needs its own queryable copy of Solana's history.
Looking back, and ahead
This release didn't come out of nowhere – we've been building toward a more open and performant Solana since 2021.
Triton's Yellowstone gRPC introduced streaming on Solana, BlockMachine pushed latency below block time, and Old Faithful made the chain’s complete ledger accessible to everyone.
RPC 2.0 stands on these and many more pieces we've tuned over the years, aiming to enable every vertical of the ecosystem to ship faster, more affordably, and more reliably:
- Solo builders can develop expressive apps from a laptop by scoping a Postgres instance to the programs they need
- Heavy-traffic teams can pair a single Dragon's Mouth stream with self-hosted read pipelines for flat-cost queries against their own infrastructure
- Providers can drop this performant layer into their stack without the years of R&D and engineering investment
- Institutions can deploy the path inside their perimeter, audit and control it end-to-end
The new Solana RPC working group, formed by the Foundation and community members to improve the read layer in the open, gives this work a permanent home.
And it won't sit empty: more code from Triton and other members will move there soon. We think the ecosystem grows fastest on open infrastructure, and we're proud to be a key part of yet another shift toward it.
Get started
Both repos are now live under the solana-rpc organisation. Pair a streaming endpoint with self-hosted Superbank or Cloudbreak, or use Triton's managed version for zero operational overhead.
If you want to self-host, RPC 2.0 modules include operator-focused documentation on building, configuring, and running these services in production.
- Build instructions for the deployment-ready binaries
- Configuration reference for every flag, env var, and config file option
- Example configs covering each supported setup
- Docker-based local setup for development
- Troubleshooting guides for common errors
READMEscovering architecture, quick start, and how the pieces fit together
Superbank also ships ClickHouse schema files for single-node, cluster, and replicated topologies, plus a k6 test suite for load, validation, stress, soak, and spike scenarios.
Two deep dives are coming next in the Rethinking series: design choices and self-host walkthroughs for Cloudbreak and Superbank.
Follow @triton_one on X so you don't miss them.