

TL;DR
- When you stream Solana data, most of your latency comes from the replay stage, where every RPC node re-executes transactions to rebuild account state
- Agave 4.0 moves signature and PoH verification off replay's hot path, which speeds up every gRPC stream that runs through it
- Anza's own metric mean_replay_blockstore_us drops from ~130ms to ~50ms on v4.0, almost a 3x cut in how long the replay thread is busy per slot
- On our side-by-side test against v3.1, v4.0 was 2-9ms faster at P50/P90/P95 on both accounts and transactions, measured across all Solana updates
- Three more v4.0 improvements worth knowing about:
- XDP completed audit and is ready for 100M-CU blocks (SIMD-0286)
- Snapshots unpack with direct I/O by default: faster startup and less page-cache pressure
- Serialisation swapped from bincode to wincode on hot paths, a lot of smaller stalls are gone
- Triton runs v4.0 on our beta gRPC endpoint, so you can leverage the early performance gains before the official mainnet rollout
- Supported regions: New York, Pittsburgh, Amsterdam, Dublin, London, and Singapore
Solana data flow recap
Before talking about improvements, here's a quick recap of how data reaches you on Solana.
First, the leader processes transactions and sends them out as shreds in real time. Shreds carry only the transactions themselves, because account deltas would significantly slow down data propagation. That means every RPC node has to re-execute those transactions locally to rebuild account state before streaming it to you.
That work happens in a stage called replay, with its substages shown below. Agave fires a Geyser callback at each substage, and Yellowstone gRPC streams the data out to you.
Replay is also where most of the latency lives, because of account locks: a transaction writing to an already-locked account has to wait for the first one to finish, a third waits for the second, and so on, cascading into delays on popular accounts like pump.fun AMMs.
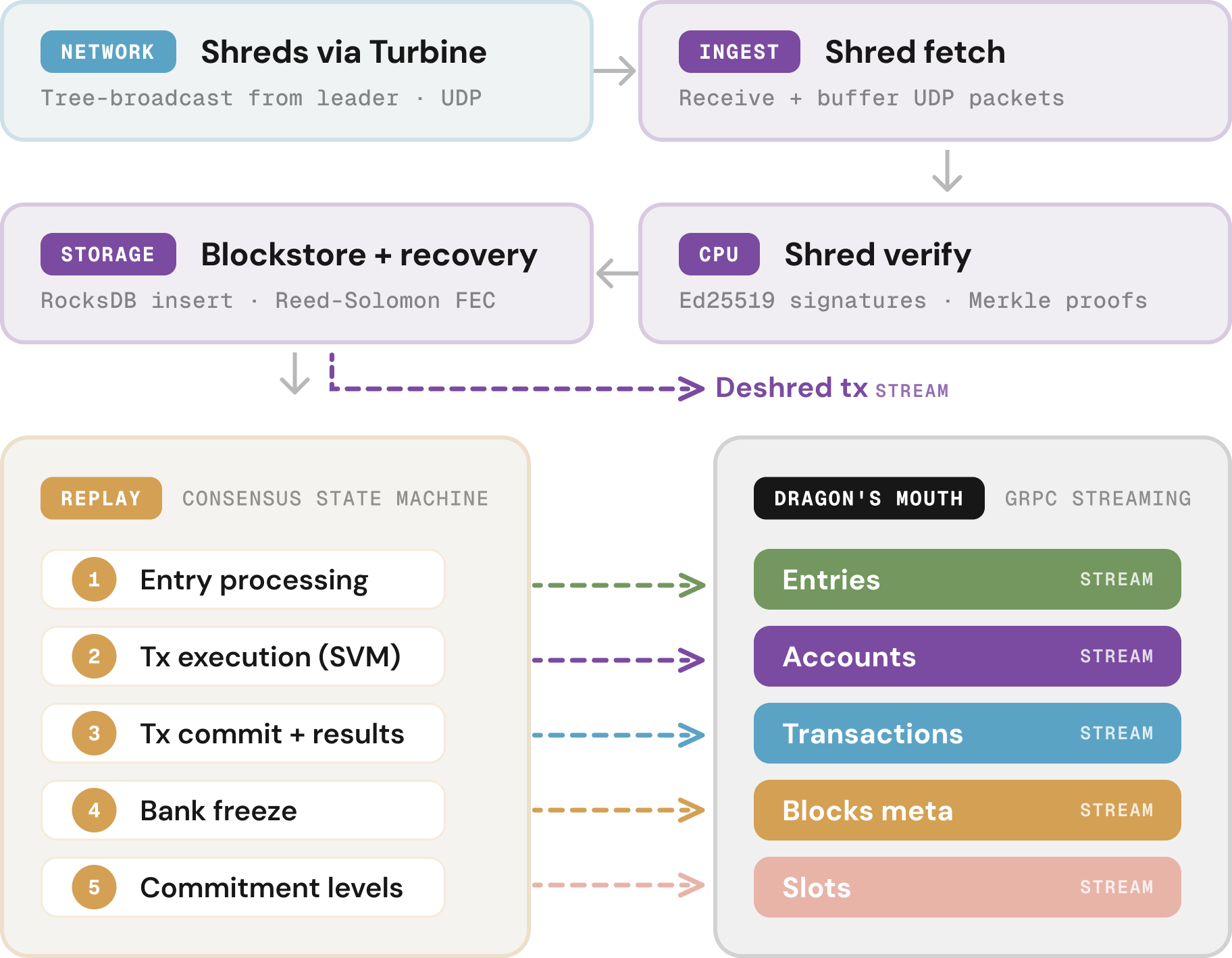
As you can see, our new Deshred endpoint sidesteps this entirely by delivering transactions straight from Blockstore, before Replay starts (learn more).
However, for the streams that run through Replay, there's good news: the pipeline itself is speeding up.
How (and by how much) did Replay get faster in Agave 4.0?
Two targeted changes in v4.0 moved the heaviest verification work off replay's hot path and onto background threads. Anza's metric mean_replay_blockstore_us shows an almost 3x reduction in how long the replay thread is busy per slot, dropping from ~130ms to ~50ms!
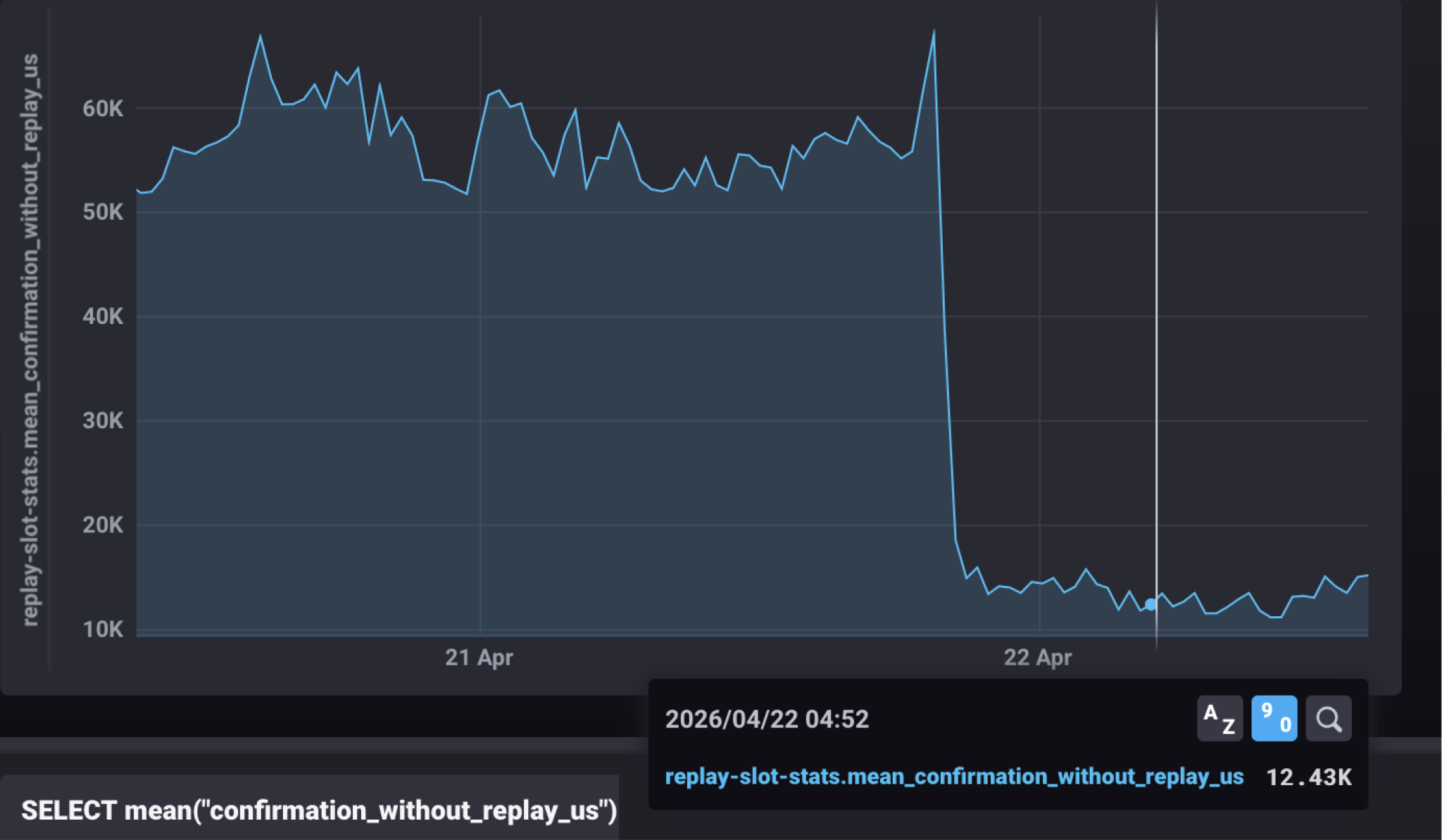
Here's what's behind it.
Async entry verification (PR #10723)
Replay used to verify the PoH hash chain inline, on the same thread handling everything else. v4.0 introduces AsyncVerificationProgress, which dispatches hash-chain verification onto rayon background jobs (in parallel).
Replay fires off verification, keeps processing transactions, and joins on the result only when it needs the answer, removing a serial blocker on the hot path.
Async transaction signature verification (PR #10947)
Ed25519 signature checks scale with the transaction count, so busy slots meant the replay thread was tied up on signature checks for much longer before it could do anything else.
v4.0 reuses the same AsyncVerificationProgress infrastructure to push signature verification onto the background path. Replay no longer waits on sig checks before moving to the next batch, speeding up both typical and the “worst-case” slots.
What it means for streaming
Yellowstone gRPC stream forwards updates the moment replay releases them, so a faster replay is a faster stream by default.
To show the change explicitly, we ran Agave v3.1 and v4.0 side by side against the same live mainnet feed, matching against all Solana account updates and all Solana transactions, matching them 1:1.

For trading infra, MEV bots, and liquidation monitors operating in the 1-to-10ms band, that's a direct win on every workload with zero code changes.
Other notable improvements in 4.0
A few other v4.0 changes matter for performance. Triton's beta gRPC endpoint is running all of them today if you want to test ahead of the mainnet launch (how to test it on Triton before it goes live).
XDP: audited, tested, and ready
XDP is a kernel-bypass path for Turbine. A small eBPF program sits inside the NIC driver, catches shreds the instant they land, and hands them to the validator through a shared memory ring, skipping the usual sk_buff allocation, stack walk, and socket-buffer copies.
For the full technical picture, Harsh Patel's two-part write-up is worth your time (part 1, part 2).
In short, XDP first shipped as experimental in Agave 3.0.9, got paused for a stability patch, and is now ready for the network's next jump. In Brennan's words, XDP "has completed audit, been tested under various configurations, and is ready to rip 100M CU blocks."
The numbers coming out of production are striking: on one of the largest validators, XDP took Turbine retransmit from around 600ms down to ~0.8ms.
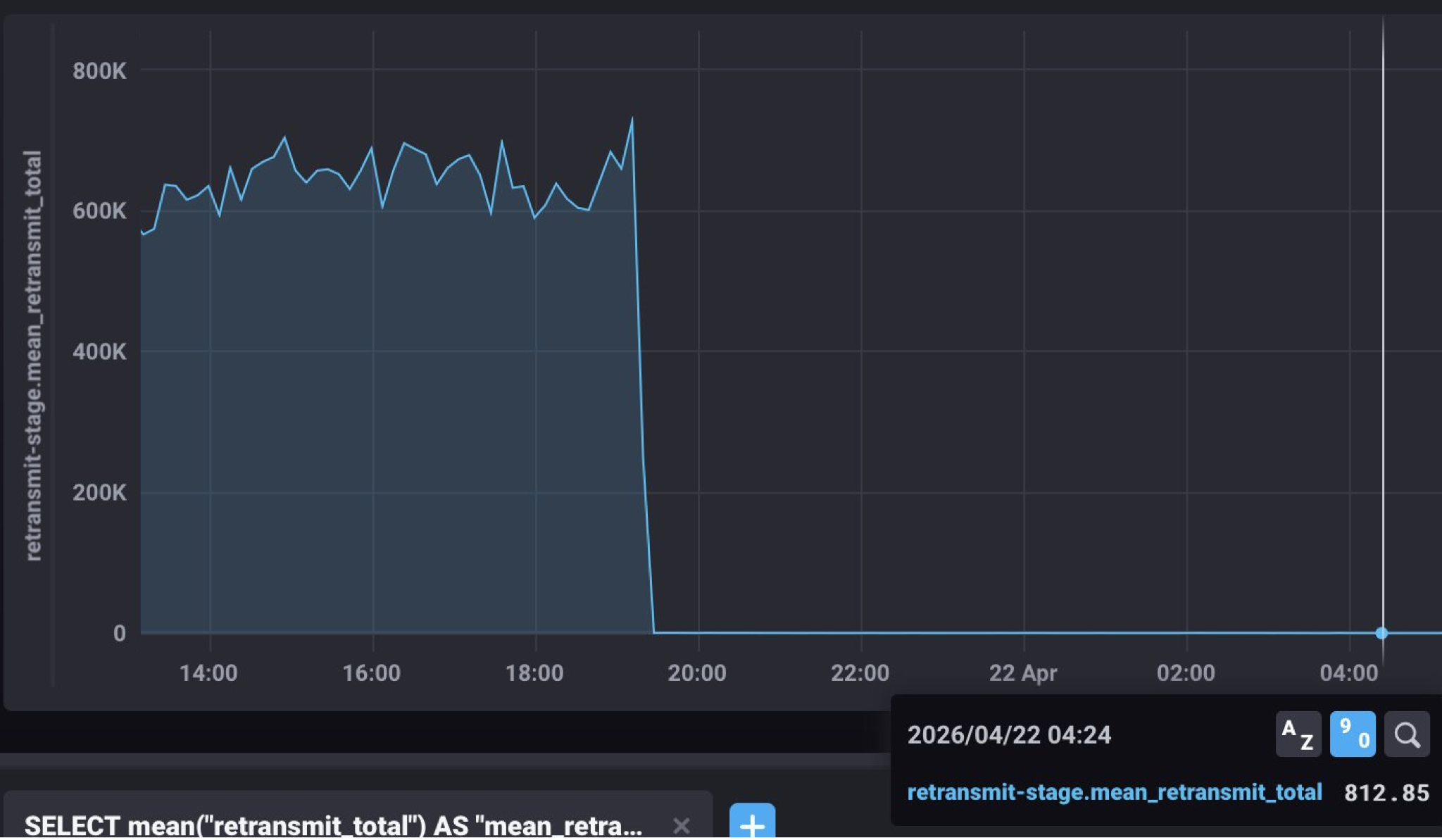
For anyone consuming Solana, that shows up as faster block propagation, fresher data, and less network-induced jitter while a block is in flight across the cluster.
Snapshots unpack with direct I/O by default
When a validator reboots, it rebuilds account state by unpacking a snapshot archive. Before v4.0, that unpack ran through the OS page cache, which evicted hot account data and added memory pressure to whatever else the validator was doing at the time.
In v4.0 it uses O_DIRECT, skipping the page cache entirely. Startup is faster, and the validator's hot state stays resident, so read-path tail latency holds up better in the minutes after a bounce.
Serialisation: bincode to wincode on hot paths
Serialisation turns in-memory Rust objects into byte streams for disk writes, network sends, and RPC responses. Agave has used bincode for this for years.
On the paths where serialisation runs most often, v4.0 switches to wincode, a newer library that does the same job with fewer CPU cycles per call
Test 4.0 today on Triton
We've been running v4.0 internally, so we made it available now on our beta cluster, giving you an opportunity to leverage the v4.0 gains on your own workloads before the mainnet rollout:
- Supported regions: New York, Pittsburgh, Amsterdam, Dublin, London, and Singapore.
- To connect, point your existing client at grpcbeta-api.rpcpool.com + token
If you don't have an endpoint yet, you can self-onboard in under 2 minutes:
Get an endpoint