
TL;DR
- Every gPA call on a standard node full-scans the entire account set. It's slow, it's costly, and the workarounds burn more bandwidth than the call itself
- Custom indexes fix this, but require a dedicated Agave node at $3,000+/month, making it out of reach for most teams
- Steamboat is Triton's account indexing engine, purpose-built to make account reads fast and accessible from shared infrastructure for every Solana builder
- gPA, gTABO, and gTABD with SPL Token fast-paths are served from indexed lookups through PostgreSQL, decoupled from the Agave validator
- Steamboat watches your existing traffic and builds the indexes automatically once the pattern reaches a frequency threshold
- At Triton, there's no premium for indexed reads. All account queries cost the same as a standard RPC call: $10 per million requests + $0.08/GB bandwidth
- Steamboat is available on all Triton plans today, and will soon be open-sourced under the AGPL licence for the community to self-host and build on
The problem with getProgramAccounts
If you're building a user-facing Solana application, whether that's a wallet, a DeFi dashboard, a marketplace, or an analytics tool, you've run into this: you call getProgramAccounts with a set of filters, and the RPC node scans every single account owned by that program, checks each one against your filter, and then returns the matches.
For a program with millions of accounts, that's a full table scan on every request. It's slow, it strains the node, and providers are forced to rate-limit gPA to keep the infrastructure standing, with some charging gPA calls at 10x the cost of a standard RPC request.
The fix has always been obvious: build an index.
But on Solana, building indexes on account data has required running an Agave node with validator-class hardware (512+ GB of RAM, fast NVMe, high-bandwidth networking), the operational overhead of keeping it all in sync, and a monthly bill of $3,000+ just to serve reads.
That puts the most optimal solution out of reach for most teams. Early-stage projects, single developers, bootstrapped startups, and anyone without the budget or ops capacity for a dedicated node have had no choice but to accept slow, throttled, and expensive account reads.
Steamboat removes that barrier.
What is Steamboat
Steamboat is Triton's account indexing service that delivers account queries up to 50x faster by serving them from tailored PostgreSQL indexes instead of Agave's key-value store. It runs on a separate infrastructure from the validator, making custom indexes available on shared endpoints for the first time.
What Steamboat covers today:
- getProgramAccounts with memcmp and dataSize filters, served from indexed lookups instead of full scans
- getTokenAccountsByOwner and getTokenAccountsByDelegate, with Token and Token-2022 queries automatically optimised via denormalised columns
- Dynamic indexing that builds indexes automatically from your query traffic, with no manual setup or index requests to file
- Complete account state from the first query, bootstrapped from a Solana snapshot and kept current via a live gRPC stream
Who benefits from this
- DeFi dashboards and aggregators pulling positions, pool state, and order books across protocols like Meteora, Raydium, or Orca
- Staking interfaces calling the Stake program (one of the heaviest gPA targets on the network) to display delegations, rewards, and validator state
- Wallets and portfolio apps querying token accounts to display balances, delegations, and holdings
- NFT marketplaces and explorers querying listing and metadata accounts from marketplace programs
- Analytics and monitoring tools snapshotting account state across programs for trend analysis, alerting, or compliance
- Bootstrapped startups that need reliable account reads without the budget for a dedicated node
Steamboat vs Agave
| Agave | Steamboat | |
|---|---|---|
| gPA avg latency (100KB–1MB responses) | 2,488 ms | 205 ms |
| gPA P90 latency (100KB–1MB responses) | 6,583 ms | 278 ms |
| gPA avg latency (jsonParsed) | 6,276 ms | 314 ms |
| Custom index cost | Dedicated node, $3,000+/mo | Included on all Triton plans |
| Custom index setup | Manual: file a request, wait for configuration | Automatic: built from your traffic |
| Developer workarounds | Fetch pubkeys via dataSlice, batch-load separately, handle retries | None. One call, one response |
| Code changes | - | None. Same methods, same filters |
Benchmarked from our integration test suite, including index creation on the fly. Times include network response time.
How it works
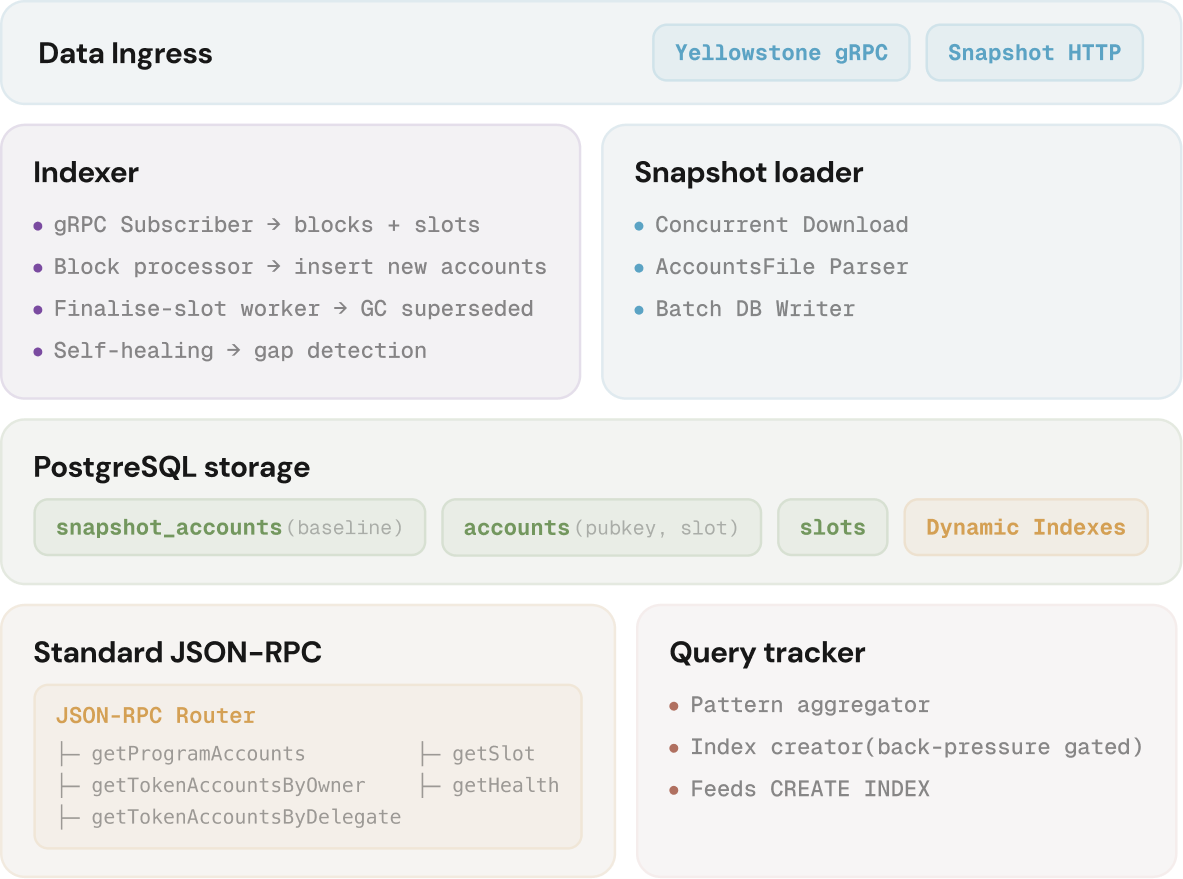
Steamboat runs on separate infrastructure from the Agave validator, which is what makes indexed reads affordable on shared endpoints and scalable as the network grows. It pulls account data via gRPC (Dragon's Mouth) into PostgreSQL and serves your queries from there.
Five components handle this:
Ingest. When a Steamboat instance comes online, it loads a full Solana snapshot and then subscribes to a live gRPC stream for ongoing updates. If the stream drops slots, the ingester detects the gap and backfills automatically.
Store. Account state lives in PostgreSQL, natively supporting dynamic index creation, partial indexes, and DISTINCT ON queries. The dataset stays bounded – only the latest version of each account is retained, with superseded versions garbage-collected on finalisation.
Track. A standalone query tracker watches your query traffic and counts how many times each filter pattern appears. It coordinates across multiple API instances and reports recurring patterns to the indexing layer.
Index. Once a filter pattern crosses a threshold, a tailored PostgreSQL index is created for it, and matching queries skip the raw scans from that point on.
Serve. A stateless JSON-RPC layer takes your standard calls and routes them to the right database. Nothing changes on your end.
Get started
If you're on Triton, Steamboat is already behind your endpoints, serving your queries faster and building indexes automatically as your traffic flows.
If you're not on Triton yet, self-onboarding is easy and takes ~2 minutes.
Get an endpointFor questions about custom configurations, program-scoped instances, or how Steamboat fits your architecture, reach out to support from your customer dashboard.
FAQ
Does Steamboat change the RPC API? No. It serves the same JSON-RPC methods (getProgramAccounts, getTokenAccountsByOwner, getTokenAccountsByDelegate) with the same request and response format. Your existing code works without changes.
How do I know if my query is hitting an index or doing a full scan? If you're on a Triton endpoint and querying a program that Steamboat is ingesting, your queries are routed through Steamboat automatically. You don't need to opt in or change your request format. The auto-indexer monitors your query patterns and creates indexes for recurring filters; once an index exists, subsequent queries with the same pattern hit it directly instead of scanning.
How is Steamboat priced? Account methods served through Steamboat are priced the same as any standard RPC call: $10 per million requests + $0.08/GB of bandwidth. This applies regardless of whether your query goes through a custom index or not.
Why is my gPA still slow for some programs? If you're querying a program or filter pattern that hasn't been indexed yet, the query may still fall back to a scan. On dedicated endpoints, you can work with us to scope your instance to exactly the programs you need.
What about compressed NFTs and Bubblegum? Compressed NFT data lives off-chain in transaction logs, not in account state. Steamboat indexes account data, so Bubblegum is handled separately by the DAS API.
Can I create any index I want? Any memcmp filter your application sends is eligible for indexing. The auto-indexer handles patterns that recur above a threshold. For less common patterns, reach out and we'll help you find the best setup for your use case.
Will Steamboat be open-sourced? Yes. Steamboat will be open-sourced soon under the AGPL licence as part of the Yellowstone project. Once available, teams will be able to run a self-hosted instance on commodity hardware. Even a full-chain instance with hundreds of query patterns fits in roughly 700 GB of storage, which can run on a single PostgreSQL node for under $400/month.
Is Steamboat new? Steamboat has been powering custom gPA indexes for Triton customers for some time. What's changed is the architecture: it now runs on separate infrastructure from the validator, builds indexes automatically from your query traffic, serves token queries via SPL fast-paths, and is available on shared endpoints.
Should I use Steamboat or gRPC streaming (Dragon's Mouth)? Steamboat serves queries on demand for the current account state. Dragon's Mouth streams updates in real time as state changes on-chain. Many applications combine both: call gPA through Steamboat to load the full picture, then subscribe via Dragon's Mouth to keep it in sync without polling.