


What you're reading describes the end state: how Solana's read layer will work when this project is complete. We're building it through 2026 and shipping in stages. Follow blog.triton.one, @triton_one on X, and GitHub for updates.
Want to build on it before the open-source releases? Get a Triton endpoint.
TL;DR
- We're proud to announce RPC 2.0 to rebuild Solana's entire read layer from the ground up
- RPC 2.0 is the most significant infrastructure upgrade since Solana launched: by removing reads from the Agave client entirely, we're delivering a purpose-built read layer that's faster, cheaper, and far more expressive
- It'll have two modules, matching the two places you read on-chain data from: accounts (current state) and historical (everything since genesis)
- The accounts module replaces full table scans with adaptive indexes that build themselves from your query traffic, lets you scope ingestion to just the programs you need, and serves the same JSON-RPC methods developers already use
- The historical module puts the full Solana ledger into a columnar engine optimised for how Solana apps actually query history, delivering recent data in milliseconds and the complete chain from genesis, affordably
- Everything ships open-source under AGPL, managed through a neutral RPC organisation run by the Solana Foundation
What's holding the read layer (and every app built on it) back
Every balance check, transaction lookup, and token list on Solana runs through the same read architecture the chain shipped at launch.
Solana's engineering focus has rightly been on the execution engine, making landing transactions reliable and fast and, naturally, the read layer grew up around it. It's been serving the ecosystem well for years, but at the scale Solana operates today, it's reached its limits.
Monolith issue
Currently, RPC nodes handle everything: consensus, state management, ledger storage, and your RPC queries in a monolithic process. When you need to scale reads, you scale the machines with validator-class hardware (768 GB of RAM, fast NVMe, high bandwidth) just to answer queries.
It's expensive for providers and end users alike, wastes resources on work the node shouldn't be doing, and slows data propagation across the network as more RPC nodes are deployed.
Expressiveness constraint
Standard JSON-RPC still offers the same limited set of query patterns it launched with. That's enough to get data in and out, but not enough to differentiate. And when every builder hits the same constraints, the apps they ship look alike for a reason.
Fragmentation problem
To get beyond those limitations, you have three options:
- Run your own unstaked nodes and hire a DevOps team
- Pay for dedicated infrastructure from a vendor
- Tie yourself to a closed-source API and hope the terms don't change
With those barriers in place, fewer developers attempt the ambitious. And those that do end up solving the obvious problems behind closed doors, wasting collective effort that could go toward building things users actually want.
When Solana launched, the vision was simple: developers build the frontend, on-chain programs handle the backend, and a standard RPC API connects the two. That promise drew many builders to Solana, but the API never evolved to support it.
That original vision is exactly where we're headed now.
The foundation for what’s next
If you've been following Solana infrastructure, you know the RPC 2.0 conversation has been going on for years. That's because replacing Solana's read layer doesn't start with the read layer.
It starts with being able to get data out of the validator in real time, and that didn't exist at launch.
Anza built Geyser, a plugin interface for streaming data out of the validator, to solve that. But building production infrastructure on top of a low-level primitive meant solving fork resolution, network transport, and block ordering before you could think about storage or query engines.
That's how Yellowstone gRPC (Dragon's Mouth) was born.
We built Yellowstone gRPC to give the ecosystem a standardised, higher-level interface for consuming Solana data over the network. From there, we released the Block Machine library for handling forks and edge cases in the stream and Old Faithful for public history from genesis.
All of it is open source and widely used across the ecosystem, including by other providers.
These tools, their adoption, and the lessons from serving them at scale are what made RPC 2.0 possible.
Accounts module: chain state, indexed and accessible
The accounts module replaces the validator's built-in account queries with a dedicated ingest-index-serve pipeline. Here's how it compares to the three ways you can get the data today:
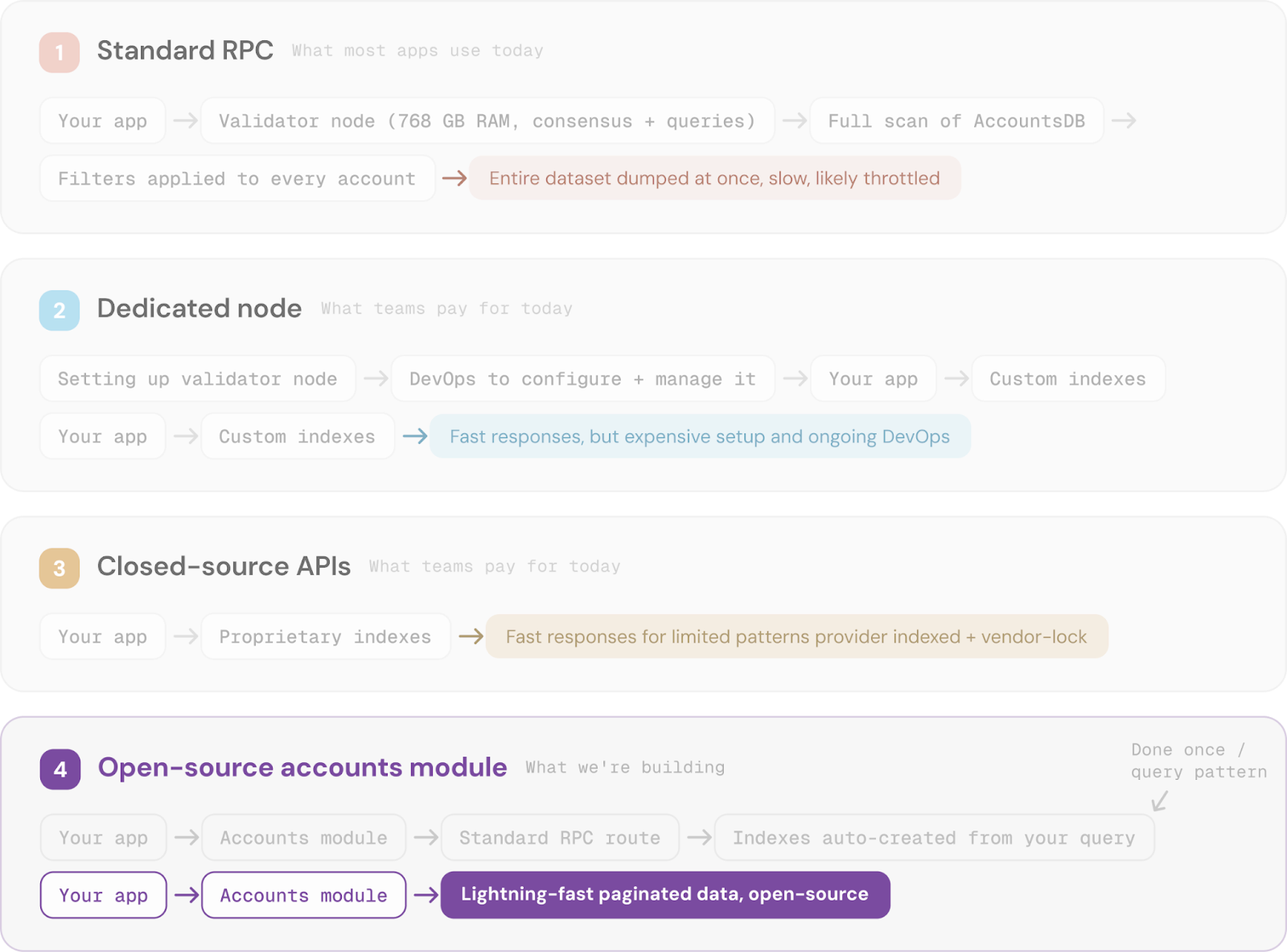
Instead of scanning every account on every query, the Accounts module builds optimised indexes matched to your application's query patterns. Once an index exists, every query hits it directly rather than walking the dataset. The result is predictable, low-latency reads at a fraction of the cost, removing the struggles of:
- Bandwidth-heavy scans on every read
- Unpaginated responses that break when new blocks land between pages
- Provisioning validator-class hardware just to serve account data
- Throttling getProgramAccounts to prevent infrastructure collapse
Here's how the accounts module will look under the hood:
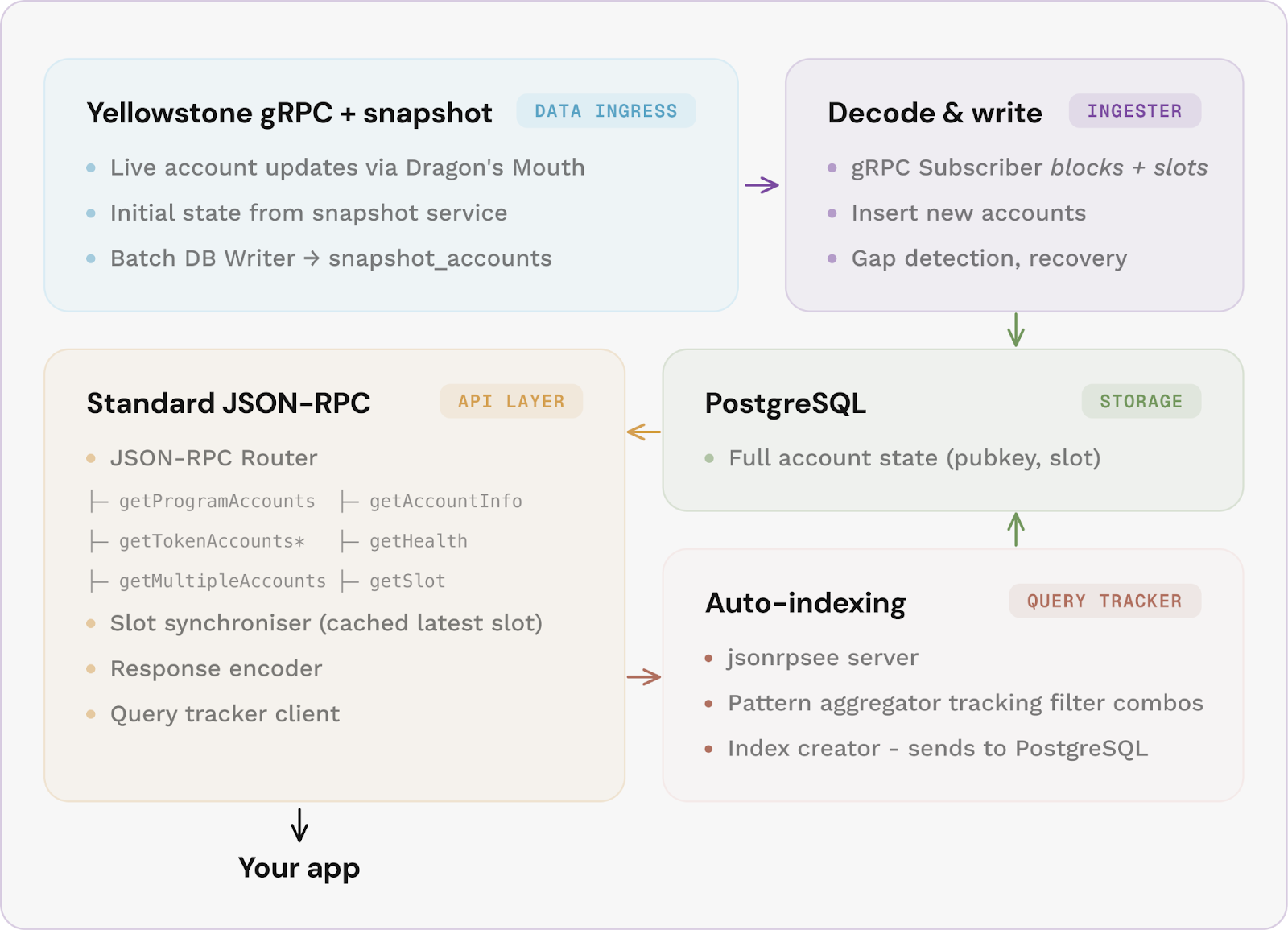
Account updates stream in via Yellowstone gRPC, with a snapshot loader seeding the full account set on first startup, so queries return complete results immediately.
The indexer writes everything to PostgreSQL, and a separate Query Tracker monitors your application's data queries. When it sees a filter pattern used often enough, it creates a targeted index for it. Token queries automatically get their own optimised path.
If the data stream drops slots, the indexer detects the gap and recovers from a snapshot without manual intervention. Ingestion can be scoped to specific programs, so you only store and index what your application actually uses.
And because each layer runs independently and scales on its own, a system running the Accounts module can handle far more load than an Agave-based setup.
Historical module: every transaction since genesis, queryable in milliseconds
The historical module handles the other side of the read layer, looking up past events such as blocks, transactions, or signatures.
Before diving into the architecture, let's look at one of the most notorious historical problems on Solana: getting a wallet's transaction history.
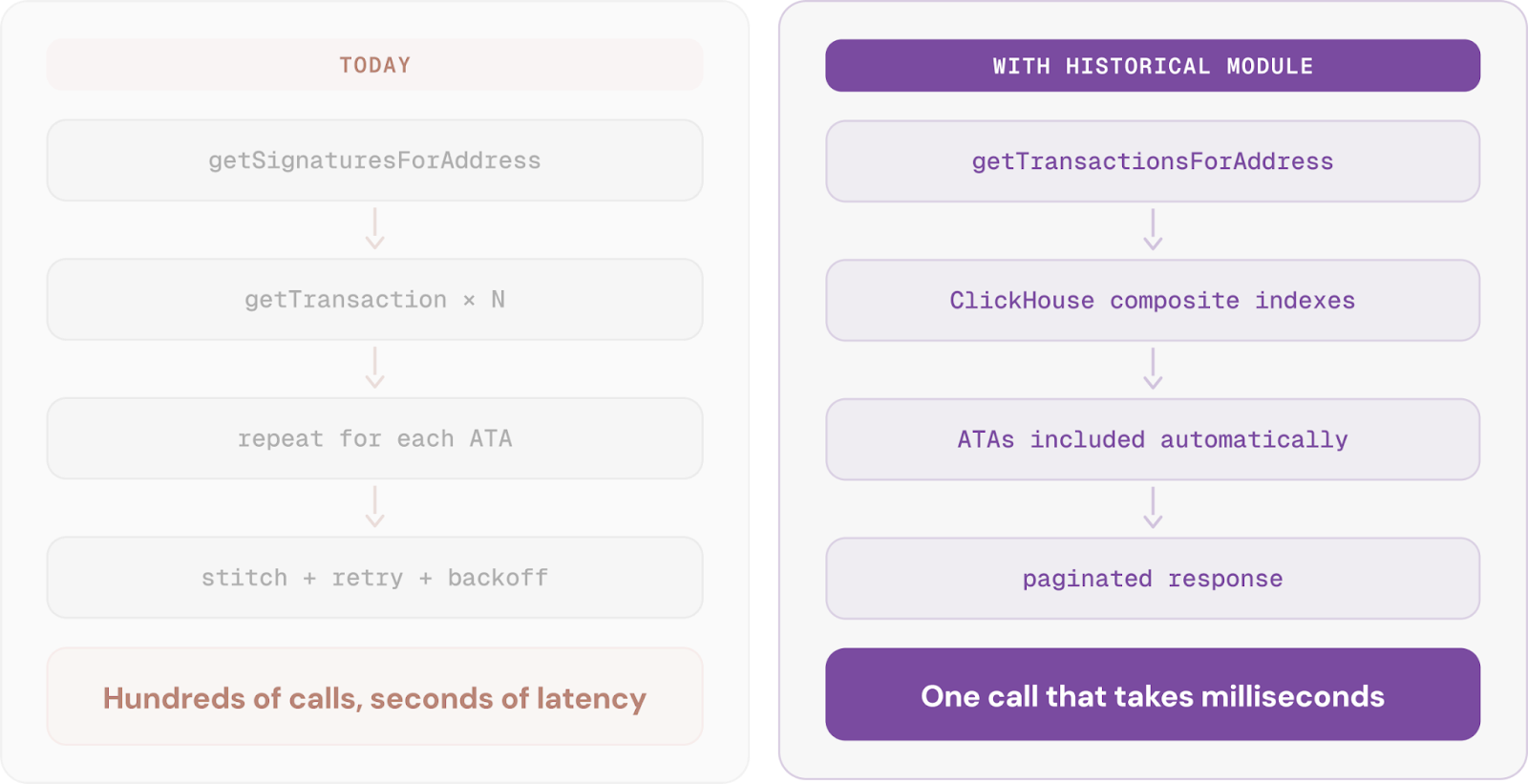
This is the classic N+1 query problem. A wallet with a few hundred transactions turns into thousands of individual RPC calls. At Solana's scale, even simple lookups add up fast in your RPC bill.
Outside of solving the above with just one call, the historical module addresses several other long-standing problems:
- Current setups are locked to rigid backends with no way to optimise individual layers independently
- Legacy storage formats make running history expensive and operationally risky
- Key methods like getSignaturesForAddress slow down as the ledger grows past trillions of rows
- No open-source standard exists for the full pipeline of ingesting, storing, and serving Solana's history
- There is no way to swap storage engines or compression strategies without rebuilding from scratch
We plan to fix it all. And here's the architecture designed to make it possible:
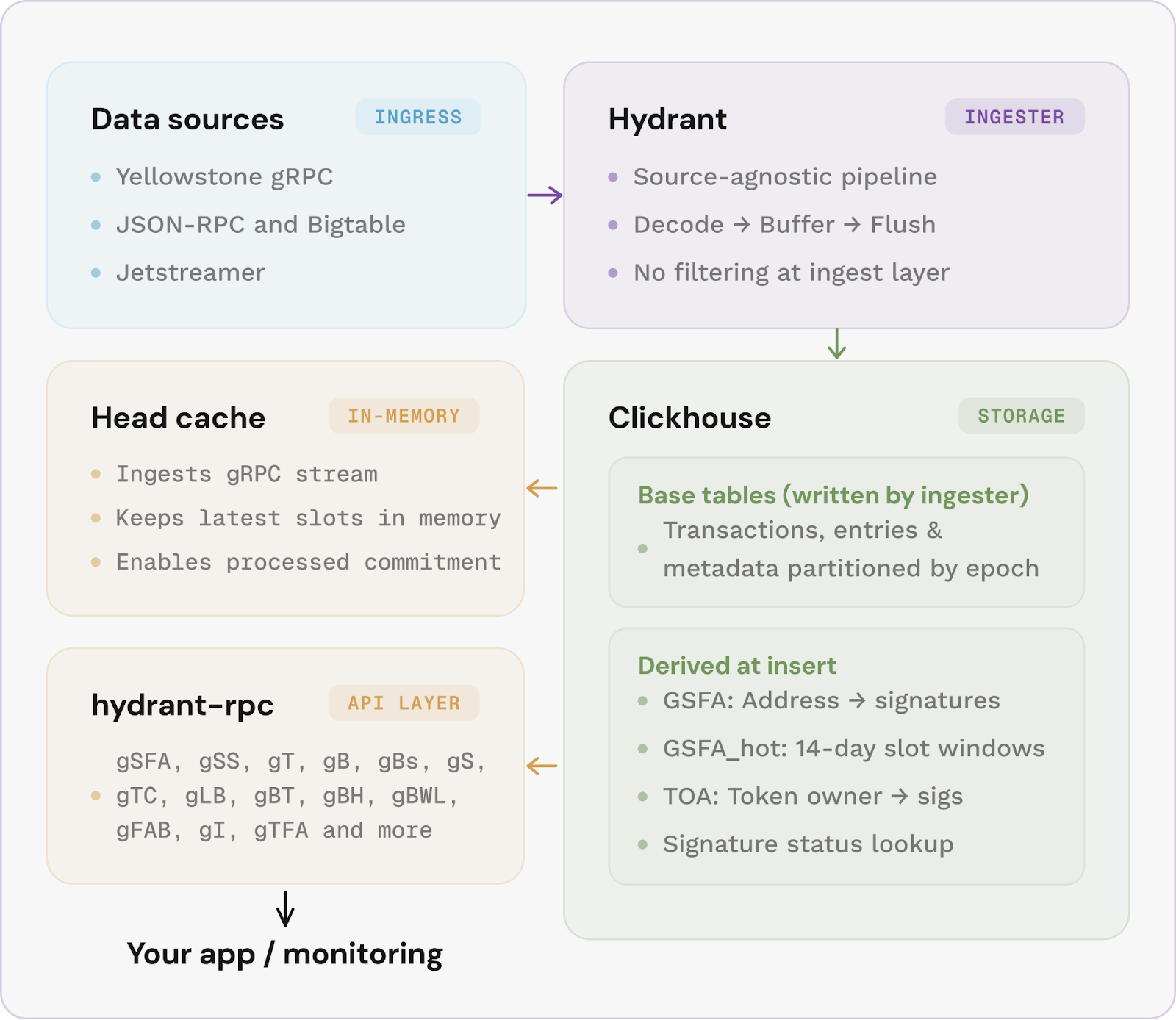
The ingester is source-agnostic: it can pull data from gRPC, Bigtable, or Jetstreamer, decode everything into structured rows, and flush to ClickHouse without filtering.
ClickHouse derives its own query-optimised views from the raw data, each one physically sorted to match how Solana apps actually read history.
Your lookup hits data already ordered by address and reverse slot, so it skips forward to exactly the rows it needs rather than scanning.
The API layer sits in front as a stateless JSON-RPC server, reading from ClickHouse or, for the most recent slots, from an in-memory head cache that serves responses in under a millisecond.
Built for all the verticals
Lending protocols, perpetuals, and trading platforms will get fast, accurate account reads to price positions and trigger liquidations. Indexed queries will replace full table scans, so your pricing engine gets the data it needs without throttling or workarounds.
NFT marketplaces will be able to run listing, bidding, and collection queries against program accounts with millions of entries and get filtered results back in milliseconds. That means real-time search and discovery for large collections will stop feeling sluggish to browse.
Explorers and dashboards will be enabled to query the complete Solana ledger at a speed matching the data production rate. Columnar storage means aggregations, filters, and deep address lookups will return orders of magnitude faster.
Analytics, researchers, and compliance teams will get to run historical analyses across the full chain without building a dedicated data warehouse. Audit trails, wallet profiling, regulatory reporting, and strategy backtesting will be possible to run against shared provider infrastructure or self-hosted using the same open-source framework with full documentation on how to manage it.
Institutions, enterprises, merchants, and funds will get a standardised, open-source read layer they can audit, deploy internally, and build reporting on top of without depending on a single vendor's proprietary API.
RPC providers will get a shared, open foundation instead of independently engineering the same indexing and historical layers. With everyone building on the same base, competition will shift to the services on top, delivering better products faster.
New builders will see the barrier drop to a laptop. The system will adapt to how your app queries data, building indexes around your access patterns rather than forcing you into a fixed interface. It will enable you to build locally, develop against real indexed data, and deploy the same code to production seamlessly.
Follow the build
This is an ongoing project through 2026, and we'll be shipping in stages. As each module reaches milestones, we'll publish technical deep-dives, deployment guides, and benchmarks.
- blog.triton.one for technical deep-dives and release announcements
- Triton One on X for updates as they ship
- GitHub for the code itself
And if you want to be running on this infrastructure before the open-source release, get a Triton endpoint and start building today.