


TL;DR
- Compliance, analytics, research, and teams that need single-digit read latency and arbitrary filters will always benefit from their own index of Solana history
- The most popular path (RPC polling) is slow, serial, rate-limited, blind to its own coverage, and expensive as costs scale per call
- While newer RPC methods like
getTransactionsForAddresssolve part of the challenge, they don't scale up to chain-wide indexing - The better alternative is Triton's Old Faithful: the only complete, verified, public Solana ledger
- Anza's Jetstreamer replays it at up to 2.7M TPS, feeding blocks, transactions, rewards, and entries straight into your local plugin. Compared to RPC polling, it's:
- Easier: known slot coverage, no query loops, no guessing at missing data
- Faster: pick your slot ranges, run many streams in parallel, at the full potential of your own wire speed
- Cheaper: run it yourself against the Old Faithful CAR archives
- We currently host the archives you can use with Jetstreamer for free, as a public good (subject to change)
- Pair with Fumarole reliable streams for ongoing indexing at the tip
Accessing Solana history
Solana's ledger spans trillions of rows and grows by millions of transactions every day, making fast, flexible access to it genuinely hard. Much of our RPC 2.0 work is aimed at fixing that, and we're open-sourcing projects like Superbank to make affordable, fast history available to everyone.
But some workloads will always need more than that: local reads in single-digit milliseconds, joins across arbitrary fields, filters on any program or account, deterministic replays, and a pipeline they control end to end.
Typical workloads that need their own copy of history:
- Compliance and tax systems running pattern detection across years of transfers
- Analytics platforms computing PnL for every trading pair on a DEX
- Risk engines replaying market conditions
- On-chain researchers building datasets for papers or models
If you're building one of these workloads, the default assumption is that polling JSON-RPC in a loop is the best way to build it (or the only way).
In practice, it breaks down on every axis that matters for indexing:
- Throttled: RPS limits bottleneck you regardless of your actual bandwidth
- Unverifiable coverage: data gaps you can't detect or backfill after the fact
- Linear cost: every block or tx is a paid call, scaling your bill with the history size
Newer RPC methods like getTransactionsForAddress patch this for specific lookups (one address, narrow windows), but they only solve part of the challenge. They don't scale up to indexing the whole chain, becoming costly and serial at scale.
The streaming (better) path
There's a much better path, and it's been available for years: stream archived blocks and transactions directly into your indexer at wire speed.
It's completely open source, carries no dependencies, costs nothing beyond your own hardware, and almost nobody talks about it (which is why it might be new to you).
It takes two tools to make the streaming path work:
| Old Faithful | Jetstreamer |
|---|---|
| The only complete, verified, and public Solana ledger built by Triton One | The Rust toolkit for streaming Old Faithful at production scale, built by Anza |
| Every block and transaction, packaged into hash-verifiable content-addressed CAR files | Plugin framework with built-in ClickHouse batching and server |
| Organised by epoch, available via public HTTP and S3-compatible mirrors | Parallel multi-threaded replay, auto-sized to your hardware |
| Free public archive for the community (subject to change) | Pluggable archive backends: public HTTP mirror or your own S3 |
By using them together, you get a complete, ready-to-run indexing pipeline at no cost:
- Query by slot, signature, or content hash, or stream every transaction and block across any slot range (cross-epoch included) with guaranteed coverage between slots
- Get a verified, gap-free chain from genesis with parent/child links checked, and PoH validated epoch by epoch
- Filter server-side by the accounts, votes, or failed transactions
- Use any destination: bundled ClickHouse, Geyser plugin, or a custom Jetstreamer plugin you build
- Out-of-the-box support for program and instruction tracking plugins
- Deterministic, bit-identical replay against any fixed range, guaranteed by CAR files
- Parallel multi-threaded stream at 2.7M TPS (benchmarked on a 64-core, 30 Gbps host)
- Runs on your own hardware against the free public archive, no per-query credits or rate limits
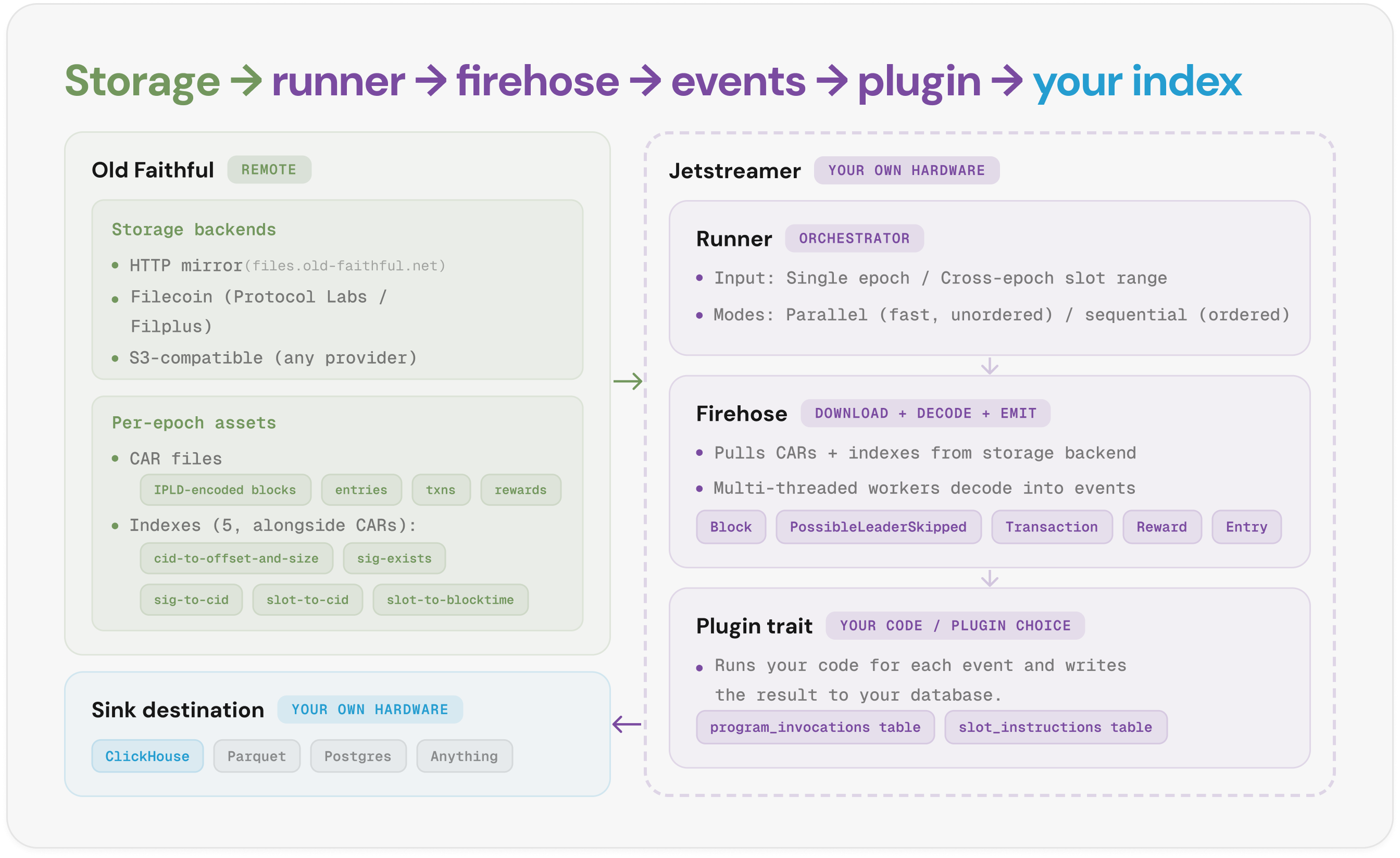
How it works
You run Jetstreamer on your own hardware. It pulls archived ledger data from Old Faithful, decodes it, and dispatches typed events to your plugin. Here's the pipeline in five steps:
- Runner takes your input. A single epoch, or an arbitrary slot range that can span epochs. Parallel mode spreads the decode across worker threads for the highest throughput, while the sequential one keeps writes in slot order
- Firehose pulls CAR files and indexes from Old Faithful. It defaults to the public HTTP mirror at files.old-faithful.net, but you can also pull from your own S3-compatible bucket.
- Multi-threaded workers decode the CARs into events. Each worker takes a chunk of the slot range, unpacks the binary IPLD structures into typed Rust events, and feeds them into your plugin. Five event types flow out:
Block,PossibleLeaderSkipped,Transaction,Reward,Entry. Each event carries its full metadata (signatures, account keys, instructions, log messages), so the plugin doesn't need to re-parse anything. - Each event fires the matching hook on your plugin. Plugin trait exposes five methods (
on_epoch,on_block,on_transaction,on_reward,on_entry), so you can write a custom plugin to filter, transform, and persist the data. Two plugins ship bundled (Program Tracking, Instruction Tracking). - Your plugin writes rows to your sink. ClickHouse is wired in by default: Jetstreamer spawns a local ClickHouse server out of the
bin/directory, and the bundledcargo clickhouse-serverandcargo clickhouse-clientaliases handle starting and inspecting it. Set a DSN to point at an external cluster instead, or use a custom plugin to write to Postgres, Parquet, etc.
Get started
Add jetstreamer to your Cargo.toml, implement the Plugin trait for your indexing logic and point the JetstreamerRunner at Old Faithful's public archive. All hook methods have default no-op implementations; override only the ones your indexer needs:
use jetstreamer::{
firehose::{epochs, TransactionData},
plugin::{Plugin, PluginFuture},
JetstreamerRunner,
};
use std::sync::Arc;
use clickhouse::Client;
struct MyIndexer;
impl Plugin for MyIndexer {
fn name(&self) -> &'static str { "my-indexer" }
fn on_transaction<'a>(
&'a self,
_thread_id: usize,
_db: Option<Arc<Client>>,
tx: &'a TransactionData,
) -> PluginFuture<'a> {
Box::pin(async move {
// filter, decode, and write to your store
println!("sig={}", tx.signature);
Ok::<(), Box<dyn std::error::Error + Send + Sync + 'static>>(())
})
}
}
fn main() {
let (start_slot, end_inclusive) = epochs::epoch_to_slot_range(800);
JetstreamerRunner::new()
.with_plugin(Box::new(MyIndexer))
.with_threads(4)
.with_slot_range_bounds(start_slot, end_inclusive + 1)
.with_clickhouse_dsn("https://your-clickhouse-dsn") // optional
.run()
.expect("runner completed");
}
Or skip the custom plugin entirely and run with one of the bundled plugins from the CLI:
# Replay epoch 800 using the bundled instruction-tracking plugin
cargo run --release -- 800 --with-plugin instruction-tracking
# Custom slot range with more parallelism
JETSTREAMER_THREADS=8 cargo run --release -- 358560000:367631999
You now have a backfilled, self-owned, open-spec index of Solana's history.
To keep indexing forward, switch to Fumarole reliable streams, a persistent, high-availability gRPC stream of live Geyser events with at-least-once delivery and subscribers that resume cleanly after reconnects.